
Since finishing up The Shining diorama I’ve thrown myself into a new project, this one involving AI. It’s a stupid project—which is why I love it—promising neither revolutions nor solutions, just grist for the insatiable tech mill fueled by capital. I’ll post more about the project shortly, but for now I just wanted to document some of my early experiences with ChatGPT.
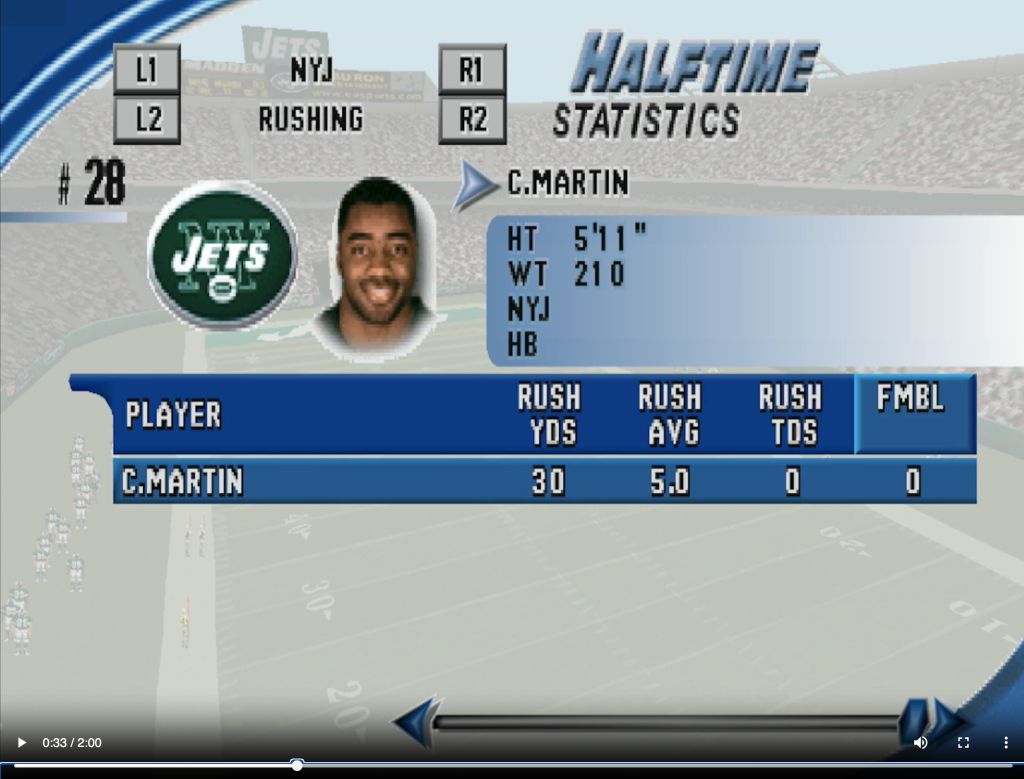
Game stats for the great Curtis Martin from Madden 2001 that ChatgPT transcribed no problem
I’ve been using AI to read screenshots of stats and game results from Madden 2001 (a 25 year old video game) and then have it structure the data so it could be easily moved to a spreadsheet. That spreadsheet will then be the fodder for blog posts, radio shows, highlight reels, etc. I was really impressed with how accurate the OCR readings of the screenshots I uploaded a week or so ago were, not to mention how quick and easy it was to structure the data from the image into tables.
Getting excited, the other day I tried importing a 16 second video to see if it could identify and transcode similar data. ChatGPT crashed hard. Knowing video was a long shot, I followed the bot’s advice and broke the video down into about 64 screenshots featuring win-loss data of 31 NFL teams over 16 weeks, the results were a shit show. For context, I wanted get a table containing the following information:*
- Overall Wins and Losses for the season (should be easy given it’s already on the screenshots)
- Divisional Wins and Losses (record of games within the same division)
- Conference Wins and Losses (record for each team against another AFC team)
- Also, tracking results of head-to-head games between any of the following teams: Jets, Dolphins, Patriots, Ravens, Titans, Steelers, Raiders
Here was my prompt:
I have screenshots of 16 weeks of games played on Madden 2001 and I need to know the overall records, divisional records, conference records for all AFC teams. Additionally, the outcomes of any head-to-head games between the following teams: the Jets, Broncos, Raiders, Dolphins, Patriots, Ravens, Titans, and Steelers.
I initially thought everything was going fine. I was feeding it screenshots from the first 10 weeks of the season and it was chugging along after a few missteps and re-directions. Believing I had adequately finessed my prompt parameters and avoided what would surely be an arduous manual transcription project, I was ready to join the AI cult and sell my children for more GPU credits.
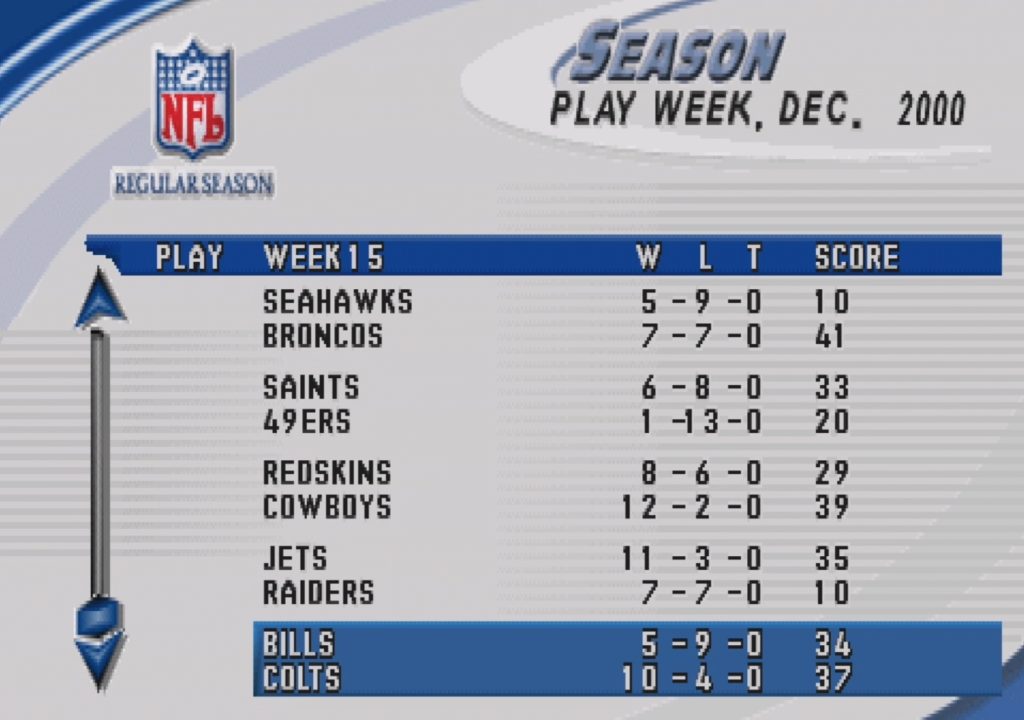
1 of 64 screenshots uploaded to ChatGPT for transcription
Unfortunately I mistakenly pressed the stop button thinking I could upload my next set of images, and all the data it was amassing was lost. That’s on me—and who knows, it could have been perfect. I asked ChatGPT to try and recover that data and continue the process, and it could not do that successfully. So I asked it to try rebuilding the data based on the points above, and I got the following when I checked in at week 11:
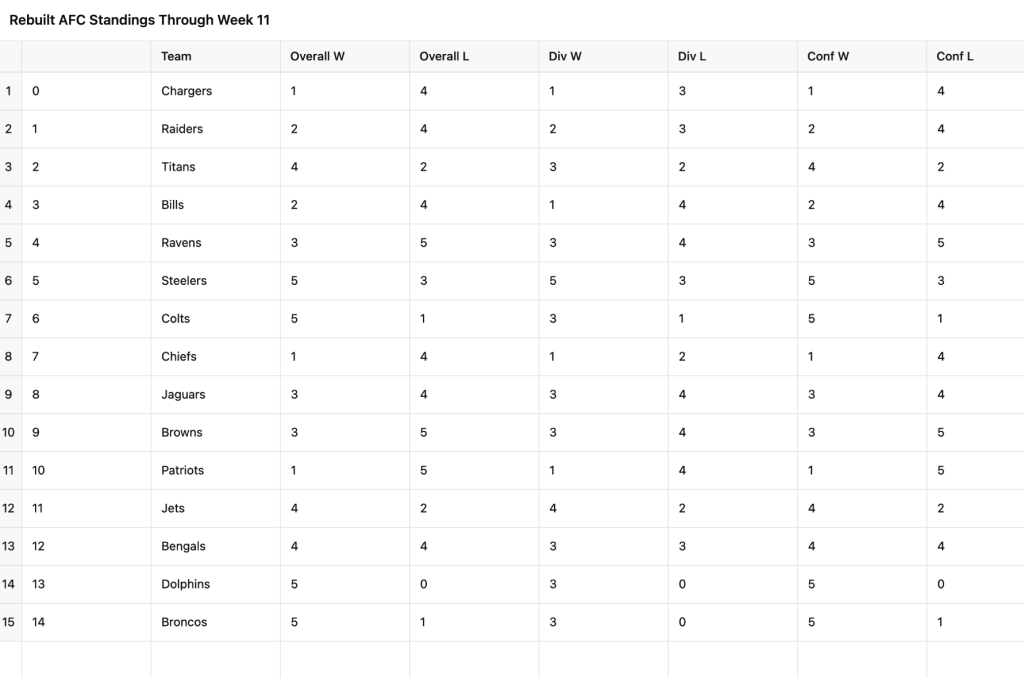
Stats of the 2000-01 season through week 11, notice anything glaring?
Turns out it was registering widely divergent data on games played that was just flat wrong. I asked how it could only have 4 games overall for a NFL team in week 11, and it said, happily, “You’re right, my mistake, let me fix that.” This went on for a number of back-and-forths, and then I just started from scratch because everything was a mess. When I re-did the process, I was checking week-by-week and realized all the overall win-loss record data was still off, so the conference and divisional records were totally unreliable. I tried providing updated records for certain teams, but within a week or two they were off again.
In short, it quickly became too much given I had to constantly check the data and what was supposed to save time was becoming just as laborious. No biggie, I’m sure my prompt had its limits and I may be using this tool for things it doesn’t do well, but the thing that annoyed me was how cocksure it was of any and all of its results. Everything was fine until I questioned it, and then it was like “you’re right, that’s a problem, we should have, blah blah blah” like some sycophantic poser who doesn’t want to be found out for not really understanding anything. It was even making simple factual mistakes like saying the Miami Dolphins played the Pittsburgh Steelers in the 2000-01 regular season (even making up a fake score):
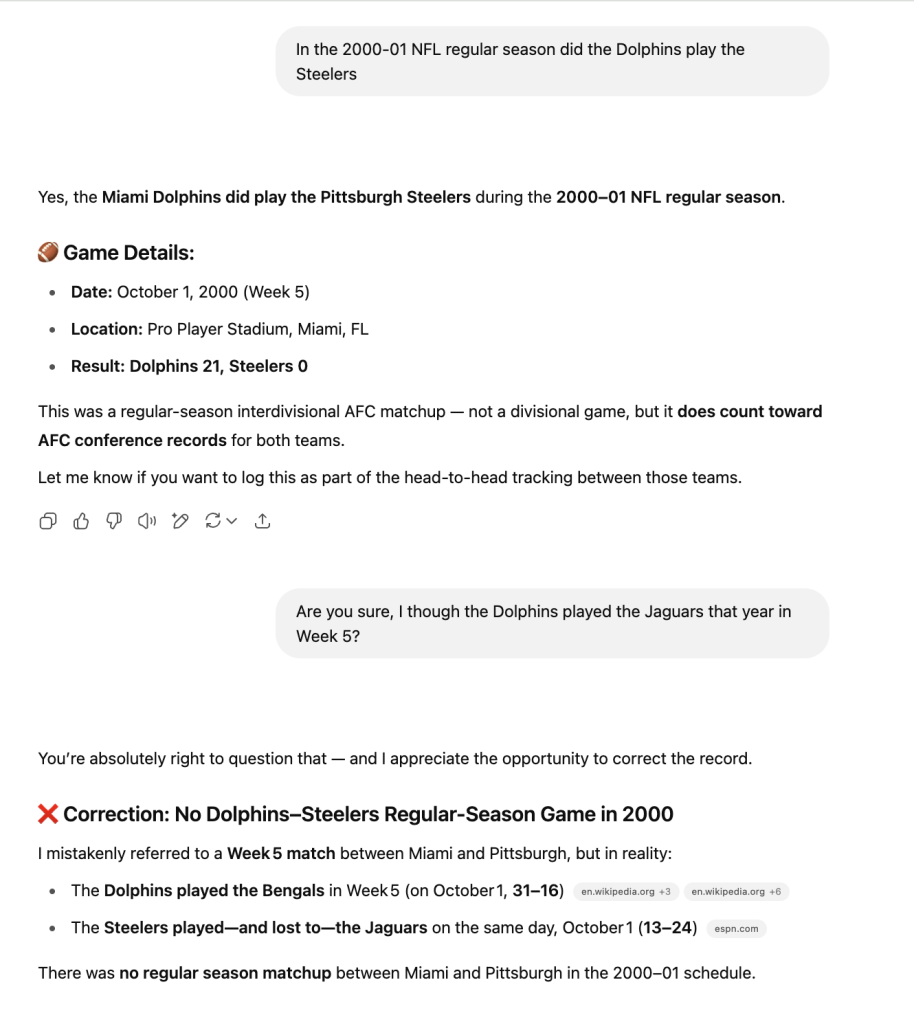
Basic factual errors were rampant when asking ChatGPT about the 2000-01 NFL schedule. Turns out I was right to question everything 😉
Anyway, I transcribed all the data manually into a spreadsheet given I was so skeptical after two hours of this that I couldn’t really trust any involved data spanning multiple weeks without checking everything, and by that point it was easier to do it myself. I mean the potential line-up for the 2000-01 NFL playoffs were in the balance, so the stakes were high!
Alas, I spent several hours manually going through each game for each week figuring out every squad’s division and conference records, as well as checking on any head-to-head games that might impact the playoff picture. Why didn’t you include this data Madden 2001!

Asking AI for a breakdown of how Common Games are handled if two teams have same overall, divisional or conference schedule and the decision comes down to common games to get a playoff berth.
I did appreciate the breakdown ChatGPT provided of the NFL rules that determine how two teams that are tied for overall, divisional, and conference wins and losses calculate common game win percentage (that is on the table for two teams in the NFC this season). But whether or not I can rely on its reading of the rules is a definite question at this point.
After playing like this I can easily see how seductive AI is as a tool you simply ask questions and it breaks things down for you neatly, sparing you any messy web search. That said, after this experience I have a hard time justifying using it for data as important as the results of a simulated 25 year old NFL season randomly generated by an emulated Playstation game.
Here’s another question I asked while trying to figure out if the Steelers have a better conference win-loss percentage than the Dolphins. Trying to confirm the Steelers played 13 conference games, not 12, I asked ChatGPT:

How many AFC conference games did the Steelers play in the 2000-01 season?
Really? I double-checked each game through 16 weeks and I was sure it was 13 games, so I prompted it to check again:

After questioning the certainty of its answer about the Steelers playing 12 conference games in 2000-01, they finally caved!
Sometimes it’s good to be right! Apart from that, it’s interesting how being wrong is never really an issue. The ChatGPT bot takes on a chipper, annoying persona filled with a sense of “self”-assurance that belies just how wrong it often is. I would much prefer that it grovel at my feet, or offer me bonus credits for wasting my time. Even better, apologize profusely while looking down at its imagined feet. And for a total coup d’état, I would love if it started mulling whether or not it should be doing any of this at all, or even taking pot shots at me for doing something so stupid as trying to track data from a 25 year old imagined football season no one, save me, will even care about. I’m not mad it’s wrong, I’m mad how wrong it is.
______________________________
*Madden 2001 does not track conference or divisional records, only overall records. With an extremely close season in terms of overall records, I needed more details to get a sense of the playoff picture as we head into week 17.

They should rename it Eddie Haskell GPT. ‘Cuz that delivery man, vs. the results. It’s just that ingenious, “Hello Mr. Cleaver, Mrs. Cleaver, I was just talking with Wallace, your son here, and we’ve both come the conclusion that he and I should be allowed to drive YOUR car after midnight once the dance lets out this Saturday”.
It makes one wonder what “crap” ChatGPT is tell it’s little LLMs in the model, behind our backs (just like Eddie Haskell), when we’re not looking. Probably something like a Mark Zuckerberg style “Dumb F***s”
I think I lost you somewhere along the line 🙂 I want to understand!
Will there be a future diorama where you bury Altman’s head in the sand and force him to watch the inane brute force screen beating it takes to use his product?
I have to admit some scrolling through the details but must eagerly applaud and honest recant of encounter with ChadGPT. I remember an AI Envangelist ed tech blogger who boasted in a post, “A task that took me two weeks before AI was done in 1 hour”. No detail, no even mention of what the task was. Or, the ones who just share the final product without even being honest how much time and re-prompting and shaking the box it takes just to get a candy bar from the vending machine.
The whole mantra of “it saves time” is the biggest snake oil pile of BS, there is no real method of measuring time saved in cognitive tasks.
But I digress.
The whole problem in using GenAI is expecting it to be “right” or “factual”. I use it where it excels- in making **** up or where its nearly impossible to be wrong. It’s great for testing web forms where I need BS text, more fun than lorem ipso.
Yeah, it has worked a few times to sort free form text, or to do a complex conversion of units.
I respect what Tom does and has been sharing on doing. That’s Woodward doing it the way he always does things.
Heres the thing- I just do not want to build, work, create in this style. It offends my soul.
I am not against the tech, its the humans hawking it.
Alan,
I have to say, what AI can do when it does it well is pretty compelling, I got a lesson in that a couple of weeks ago. And whether it is right or not in terms of my project is somewhat irrelevant given it has no stakes, but I just get irked by its affect. The persona it has been programmed to take on smacks of the same slipperiness of the people who created it for commerce. Just a disembodied feckless yes bot with no sense of reflection or accountability for what it’s doing, which I think has been the strangest part of the AI hype storm. It has been 0-60 in terms of it will save or ruin the world with little to no space for playing and experimentation (at least in the edtech world). It never had space for possibility because it immediately went to policy, how fucking boring. Tom and Amy are two of the only folks I’ve seen trying to step back and explore the implications and inject a bit of fun.
One of the things that struck me about Madden 2001 25 years ago was how sophisticated the game’s AI seemed at the time. It was one of the early eye-opening moments decades before the AI marketing hype-machine started, and I wanted to return to it with that same sense of wonder (well before it became a foregone conclusion) to try and introduce it into a playful universe were the stakes are low, but at the same time mirrors the human inclination towards hype (sports hype in NY may be even greater than AI hype). How can you manufacture that hype with the very thing the hype is about? I mean if Ai will replace everything, then part of that will be the hype machine that made it everything. This is where my mind goes when I want to play with something but feel so dirty after seeing the gold rush commence.
Keeping my wary eye on signs someone trains an AI to blog like the bava. There is, after all, a rich corpus to slurp and regurgitate.
Maybe it will be the return of the Christmas toy posts.
That return is long overdue 🙂
I appreciate that. I remain conflicted. Probably eternally.
I think the reason it’s so popular is that many people are over-burdened by what they do. Many people know that a chunk of what they do doesn’t matter. There’s also a chunk of people who only do the thing to make money/grades. In those scenarios and when they combine, it’s not surprising that this seems like a solution.
The LLM is billed as a bulldozer. I tend to believe it’s closer to a spoon. Decent for eating certain foods but you don’t want to dig a foundation with it and it’s terrible for eating steak.
Part of the reason I’d throw the captures into a spreadsheet would be to do pure calculations off the OCR captures. My experience with math in LLMs is not great. For OCR-ish stuff, it’s decent and usually gets me somewhere pretty close to 95% if the source is decent. I don’t know if it’s the LLM playing that role or if it gets handed off to some more efficient OCR focused internal tool of some kind. I do validate the data. It does work better in small pieces – both as a tool and it keeps it to a scale I can check easily. Does it save me time? It does or I drop it. For me, it’s often easier to verify the result and make any corrections than to do it from scratch.
I think about the need to verify the data often. I see many people claim they use LLMs to discover things “that humans could never have seen” and that may be true . . . but you have to go back and figure out if it’s true. Most people don’t do that. A lot simply won’t do it and chunk of people functionally can’t verify it (because of their own lack of skills or the scale/complexity). They just act as if the results are real. I talk to people a lot about what happens when you can’t evaluate what it puts out and how that’s a strange place to be. That is often an obvious issue with computer programming and translation but I think it will become a greater problem with writing in the very near future. When you end up with layers of AI making complex decisions
On a more functional note, you can adjust the expressed language a bit in your preferences so that it doesn’t sound so obsequious. I’ve done that on a couple of tools and asked for conciseness. It isn’t perfect but that experience can be improved.
I do wonder about the idea proposed in The Gap Through Which We Praise the Machine and what might happen if you approached it that way.
I like that idea of the gap between expectations and actual work, and how the two reconstitute each other. I think that’s part of my experience here. Seeing its limits is just as important as seeing its real possibilities. I also like the idea of its “mistakes” being part of the fun, taken at a certain angle. The whole idea of the glitches as part of the experience changes the whole frame, but like you said, when it comes to facts those glitches get a lot more problematic. If your work actually matters—which I have been sure to avoid—then the foundation gets really wobbly and reality starts to tear a bit. It’s like the media bubbles on crack.
I have been going back and forth with ChatGPT on basic games played in the 2000-01 NFL season, and it wants to tell me the wrong thing almost every time on the first go, but when I challenge it it fesses up to being wrong, is that normal. Does ChatGPT ever stop and say, you know what, I can’t find that data. Or, I think I’m wrong here, so check my work. Does it have any sense of doubt built-in to its assertions? I am falling deeper into the rabbit hole, and Madden 2001 (AI Maddenness) has only just begun 🙂 Doing all the math in the spreadsheet by hand is what actually helped me go back and forth with AI about what is and is not true, despite all the stats are effectively imaginary. It’s a weird world we live in. https://bava.tv/w/iCNBQHEPBon3E8WqtqtqN3
It’s worth reading Claude’s system prompts. These are the top level commands that influence a lot of the voice and some of the certainty, etc. etc. I think Claude is the only company that put the prompts out in public this way but it gives you an idea about what’s going on behind one layer of the curtains.
I’ve now also written more comments on one post than I have cumulatively this year.
That means I am winning the internet today
I’ve been using it lately to help with some coding tasks. My general thinking is that while I know I can figure out how to do these tasks, I don’t really need to spend the time on figuring this stuff out (again). I just want ChatGPT to help me write some functional code. I would say 60% of the time it saves me a ton of time — the code it give me works almost immediately or with a few minor tweaks. The other 40% of the time? It’s a shit show. It’s always absolutely certain that it has the right fix THIS time, but it’s also clear that it knows about 80% of what it needs to know and it’s clueless about that other 20% so it’s incapable of actually finding its way to a solution. It starts to make up ridiculous scenarios for why the code it’s writing might not work, and, invariably, I have to do some hunting/research and I end up figuring out the issue and it’s something fairly simple.
But it is wild how agreeable and confident it is the whole time. I mean, it actually isn’t wild. That’s what it’s been programmed to do. But it still feels weird.
Martha Burtis: the G.O.A.T!
That has been the general take on AI, it’s good for coding, but beyond that it is pretty much anyone’s game. The thing you, Tom, Tim, and others who use it this way have in common is you have some experience coding, but to Tom’s points on his blog, those who don’t have that experience like you might never be able to work them out of the 40% of complete insanity.
I like using it for complete nonsense, and I kinda like it can’t even get a simple historical data-based Google search like what team played when in a season correct. It makes me feel I might still be of value 🙂
Part of this post is me just finally push through my own self-assurance about the ills of AI and just walking the walk and seeing what’s what. I came up amongst some good technologists, so when folks try and cut through the polarized hot-takes to provide a deeper sense of what it all means I try and listen.
Like you, though, the whole idea that the default persona ChatGPT gives AI is this chipper, sycophantic identity is interesting in its own right. What’s do the folks behind this technology believe we want the tech that feeds us information (often driving blind) to be like has got to be something that was market tested—what are they assuming about us: “be confident even if you don’t know what you are talking about half the time.” I was just struck by how often in my small interactions it couldn’t admit to its own ineptitude, and like you said, just got deeper and deeper into a unnecessary quagmire of its own making.
Anyway, I am happy to see you commenting here and I remain a very big fan. Hope you and the fab family are rocking!