

Image Credit: “Actress Virginia Pearson, page 75 of the August 1916 Motion Picture magazine.” found on WikiMedia Commons
I finally got around to converting some dormant WordPress sites to straight-up HTML. This was inspired by similar efforts by folks like Adam Croom and Keegan Long-Wheeler who put their sites on a web diet of sorts. I decided to start with OpenVA, which was a working group formed by the State Council for Higher Education in Virginia in 2012 to see if we could do more in terms of affordable textbooks. The committee tried to move the conversation away from the proposed focus on a statewide deal with textbook publishers for better pricing to explore how we might highlight the myriad work already happening around open resources, open platforms, and open pedagogy in Virginia. So, rather than simply brokering a deal for discounts, the idea was to explore what is already happening with the hope there would be some broader structural/political implications for recognizing and providing targeted funding for this work.

Image credit: Tom Woodward’s “#openva hilarity”
But, alas, it was not to be (at least as part of the original OpenVA working group). After three conferences over two and a half years on the committee I was replaced, and not long after the entire effort seemed to peter out. It’s a shame because I think there were some really good people that might have done more to connect and co-ordinate the work happening across institutions in Virginia, but sometimes that’s the way these things go—and by doing this I learned that trying to implement change at the state level is just plain hard. It’s one of those things in my professional life that I had high hopes for, but was unfortunately left undone. And I am afraid will never be done given my life as a Virginia state employee has been over for more than two years.

Anyway, when I saw the group had let the site go I snatched it back up and reverted it to its original TwentyTen WordPress theme glory (wave to the haterz). This is a project I was part of that I want to preserve, but I’m not sure openva.org will see too much action anytime soon. What’s more, I installed WordFence on the domain after it had been hacked, and according to my regular WordFence emails it remains a constant target. So, I decided to make OpenVA.org the first of many archival projects I have lined up over the coming months.
There was a great thread on Reclaim Hosting’s Community forum started by Alan Levine about archiving old sites to HTML. It was suggesting how an application like Site Sucker offers a clean easy option. Which led to a discussion that Site Sucker is just a nice wrapper for a wget command in terminal. And then folks like Boris Mann chimed in noting that one thing to consider when sucking a site is that you can lose metadata like post author, time, etc. He recommended exporting to Jekyl through Github, which is an interesting alternative and something Brian Bennett is in the process of moving his WordPress to a flat file structure presently. It was a great thread, and leaves a ton to consider. I decided on using Site Sucker because it’s dead simple and OpenVA had just a few authors and not that many posts. What’s more, I’m keeping the WordPress database and files archived in the unlikely event I ever need to resuscitate the site.
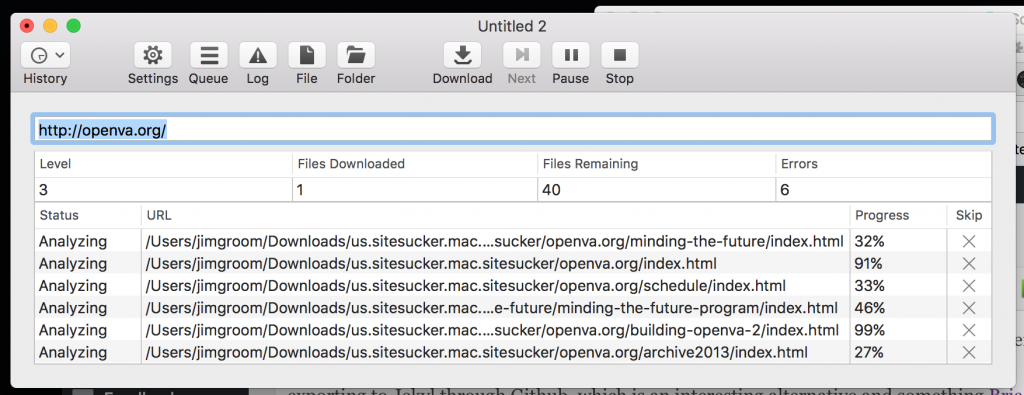
So, using Site Sucker is really as simple as adding the URL to the app and it goes through and downloads a copy of all the pages, media, CSS for the theme, etc. Once you have the archive, you can go to your web server directory that has the WordPress files and replace them with the HTML Site Sucker has generated. It is really that simple. Right now OpenVA is running with flat HTML files which decreases the risk of being hacked while giving me one less site to manage (although to be honest WordPress makes it so simple with automatic updates that it can be argued the management overhead is overstated). Anyway, after a few minutes it was done and OpenVA’s WordPress files are now archived and we are running it off flat HTML files sans database.
Although, as a bit of a cliff hanger here, I did start archiving another WordPress site with Site Sucker that was one of the the first multi-sites we ran at UMW back in 2007 (ELS Blogs) but ran into some issues. Those issues will be the topic of a future post as I work through options for archiving a WordPress Multisite given the issues that arise with outdated themes and plugins, amongst other things.

I still read your blog, if only to see if you mention my name. I guess a picture speaks a thousand words. This was a fun time and I miss you buddy. You made a good effort with OpenVA, but it IS incredibly hard. I continue to keep chipping away at things on a local and state level. Keep on archiving and keep using Twenty-Ten!
I miss you too, Andy! That picture makes me smile, and part of archiving the past is remembering what you want to focus on, and for me that picture captures the lens I want to remember our time together through. Irreverently laughing at the inability for the state to get its shit together 🙂 Big fan!