
I have to document some of what we have been working on for WordPress Multiregion (WPMR) given I’ll need to reference some of these commands and scripts in the future. One of the issues that can occur with our WPMR setups is that the database on the primary site can get out of sync with the secondary site, which means posts or comments to the primary database are not copied over cleanly to the secondary database. This is an issue for obvious reasons, but it can be hard to identify given both sites will still be running cleanly (the database does not break), it’s just that the secondary site will not have any of the latest content after the sync was broken.
This is an issue I have run into sporadically while playing with WPMR, and over the last month we have come up with a clean way to both identify when the databases aren’t replicating cleanly as well as a command to run that puts them back in sync.
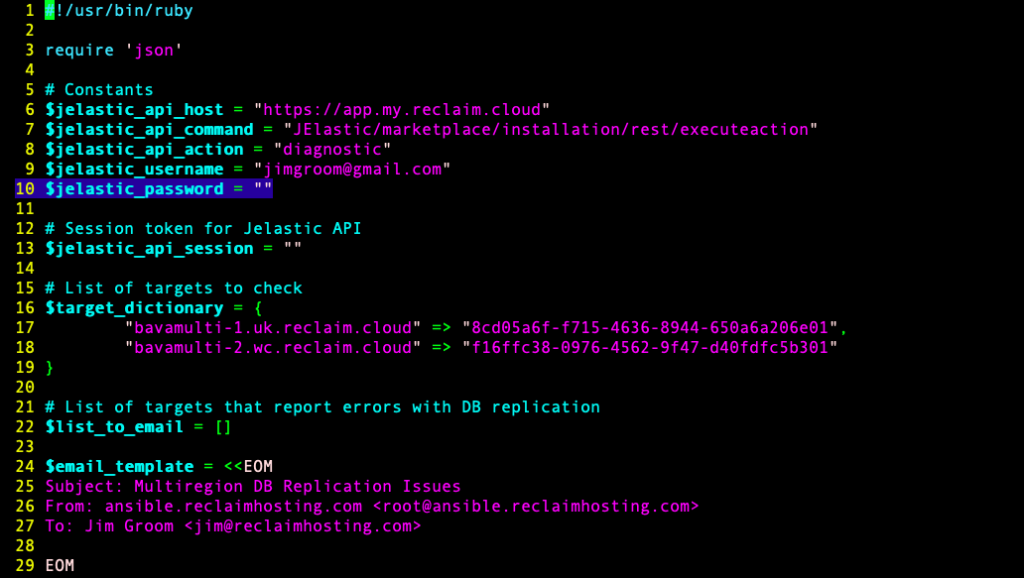
Excerpt from script to identify with WordPress Multiregion instances are out of sync
The first bit I’ll share is a script Chris Blankenship wrote that is executed regularly using a cron job to ensure the JSON output from each WordPress instance of a WPMR setup match for latest posts or comments (and we may even want to add pages to that).
#!/usr/bin/ruby
require 'json'
# Constants
$jelastic_api_host = "https://app.my.reclaim.cloud"
$jelastic_api_command = "JElastic/marketplace/installation/rest/executeaction"
$jelastic_api_action = "diagnostic"
$jelastic_username = "username"
$jelastic_password = "password"
# Session token for Jelastic API
$jelastic_api_session = ""
# List of targets to check
$target_dictionary = {
"environment.url.reclaim.cloud" => "container_id",
}
# List of targets that report errors with DB replication
$list_to_email = []
$email_template = <<EOM
Subject: Multiregion DB Replication Issues
From: ansible.reclaimhosting.com <[email protected]>
To: monitoring-notice <[email protected]>
EOM
# Get a Jelastic API session token
def signin
# AUTHENTICATE AGAINST THE API
#$jelastic_api_session = "****************************"
$jelastic_api_session = JSON.load(`~/jelastic/users/authentication/signin --platformUrl #{$jelastic_api_host} --login #{$jelastic_username} --password #{$jelastic_password} --silent true`)['response']['session']
end
# Run diagnostic of DB replication
def run_diagnostic(target_application)
api_json_output = JSON.load(`curl '#{$jelastic_api_host}/#{$jelastic_api_command}' -X POST --data 'appUniqueName=#{target_application}&action=#{$jelastic_api_action}&session=#{$jelastic_api_session}'`)
return api_json_output
end
# Send notification email
def send_email
if $list_to_email.length() > 0
email_to_send = $email_template + $list_to_email.join("\n")
`/usr/bin/echo "#{email_to_send}" | /usr/sbin/sendmail [email protected] `
end
end
# Sign out of generated session
def signout
`~/jelastic/users/authentication/signout`
end
# Main/entry function
def main
signin
for this_host in $target_dictionary.keys
diagnostic_output = run_diagnostic($target_dictionary[this_host])
if (diagnostic_output['result'] != "0") and (diagnostic_output['result'] != 0)
$list_to_email.push(this_host)
end
end
send_email
signout
end
main
This lives on Reclaim’s Ansible server at /root/cron_scripts/multiregion_db_replication/multiregion_db_replication_check-bava.rb and if I add my Reclaim Cloud username and password as well as our Jelastic API key I will be notified both via email whenever the two databases are out of sync. You can also integrate with Slack notifications, but I changed those emails given they’re particular to Reclaim Hosting’s Slack, much like the Reclaim Cloud credentials, Jelastic API key, etc.
So, now that we know when the sync is not working we need to fix it. And do that you need to run the following command on the secondary WordPress instance as root for the environment. To switch to root you need this command:
sudo su -root
After that, run the database recovery command below in screen given it can take 15-20 minutes:
screen
Once in screen, make sure the donor-ip value is the IP address of the primary WordPress instance in the multiregion setup. and then run the database recovery script:
/tmp/db-recovery.sh --donor-ip 'primary.wpmr.ip.address' --scenario restore_primary_from_primary
For example, the command for my setup looks like this:
/tmp/db-recovery.sh --donor-ip '198.244.162.213' --scenario restore_primary_from_primary
After that, the script will re-sync the databases.
What follows might be considered a wishlist. What would make sense based on this workflow is that any time the sync breaks the following three things happen:
- The Cloudflare load balancer is immediately switched from dynamic or geo-targeted steering of traffic to failover mode. This means that the traffic for the secondary server will automatically redirect all traffic to the primary environment until the two databases are re-synced.
- The database recovery script is immediately run once the out-of-sync notification is received.
- After the database recovery is finished and the script no longer shows the two databases out of sync the Cloudflare load balancer is told to resume dynamic or geo-targeted traffic steering
And with that the multi-region setup would not always need to route pools in failover order, this will happen only if there is an issue with database syncing, or any of the server instances goes down.
