
Now that I have a few instances of Mastodon running in Reclaim Cloud, I figured it was time to start optimizing them for resource usage, storage, and security. This post is an attempt to capture what I’ve done thus far—which is not much—in order to keep track of changes I am making. Also, I’ve only been tweaking social.ds106.us given the other two servers (reclaim.rocks and bava.social) are still getting their legs. I’ll probably collect some of these resources and tweaks into a more comprehensive guide, but for now this will be fairly random and incomplete.
Chris Blankenship pointed me to a recent post from the Mastodon admin Tek of the freeradical.zone Mastodon server. I dig that they run a blog to capture and share the work they’re doing, and I think the breakdown of the different pieces that make Mastodon run in the “Surviving and thriving through the 2022-11-05 meltdown” post is quite good:
Let’s take a moment to talk about how Free Radical was set up. A Mastodon server has a few components:
- A PostgreSQL database server.
- A Redis caching server that holds a lot of working information in fast RAM.
- A “streaming” service (running in Node.js) that serves long-running HTTP and WebSocket connections to clients.
- The Mastodon website, a Ruby on Rails app, for people using the service in their web browser.
- “Sidekiq”, another Ruby on Rails service that processes the background housekeeping tasks we talked about earlier [namely posting, following other users, notifications, etc.] .
- Amazon’s S3 storage service that handles images, videos, and all those other shiny things.
This nicely highlights all the different pieces that go into running a Mastodon instance, underscoring that there’s some complexity. One of the issues that Tek was running into with the influx of new users was Sidekiq was overloaded with new and various tasks, so they were not showing up in real time—essentially being queued as a result of the bottleneck. What he did was separate out the PostgreSQL database (already done back in 2017), move Sidekiq to its own machine (a lonely Raspberry Pi 4 he found around his house), and eventually moved the Redis caching service to the server hosting Postgresql to ensure it was not competing with Sidekiq for RAM. The only services left on the original 4GB cloud server were the node.js streaming service, the Mastodon website Ruby on Rails app, and the original Sidekiq service (he added more works to the Sidekiq running on Raspberry pi to go from 25 to 160 works to deal with queueing tasks). It never ceases to amaze me how resourceful and creative sysadmins can be to solve high-pressure issues like servers not working right for a community of 700 folks that are managing their social streams—it ain’t a job for the faint of heart.
What I gleaned from Tek’s experience is that breaking out the various services is essential as you scale, and it seems like the first to move was the database—which is good to know. Luckily we are only just now approaching 40 users on ds06’s instance, and we will most likely scale slowly and intentionally, so we may not have any of these issues just yet—but a behind-the-scenes peek at how freeradical scaled is really helpful if Reclaim does want to take on other instances that want to scale fast.
So, that was some good background ready and context for the tweaks I starting implementing on social.ds106.us. First things fist, I reading the scaling Mastodon doc and starting adding environment variables to the .env.production file to increase concurrent web processes (WEB_CONCURRENCY) as well as the number of threads for each process (MAX_THREADS). I read that Tek had these at 25 for concurrency, so I changed the default values of 2 and 5 respectively to 25. So far there have been no issues, but any one reading this who sees an issue let me know. Also, I real the DB_POOL would need to be at least as many as the number of MAX_THREADS, so I set that to 30.
WEB_CONCURRENCY=25
MAX_THREADS=25
DB_POOL=30
So far, so good. I then dug-in on the Scaling Down Mastodon guide by Nolan Lawson (h/t Doug Holton) which was quite helpful. In particular, I changed max database connections to 200 in the postgresql.conf file found, at least for me, at /etc/postgresql/15/main/
max_connections = 200 # (change requires restart)
I then tried using PGTune to fine-tune the database, but that brought everything down for a bit, so I quickly reverted and will need to re-visit that in a dev environment. Another thing I will be experimenting is PgBouncer in the event we start running out of available database connections. I upped the default from 100 to 200, so I am imagining this is not an immediate concern given our size, but at the same time this is also about figuring out how to optimize a server for scaling, so worth playing with in the future.
Another big piece of scaling down was figuring out how to control the explosion of files being stored in AWS’s S3. The scaling down guide pointed me to this bit in the Mastodon docs that shows you how to create a cron job to remove cached media files on a weekly basis. I ran the cron and it immediately cleaned out 2 GB of cached files. This of a possible 15 GB, bring the total closer to 13 GB.
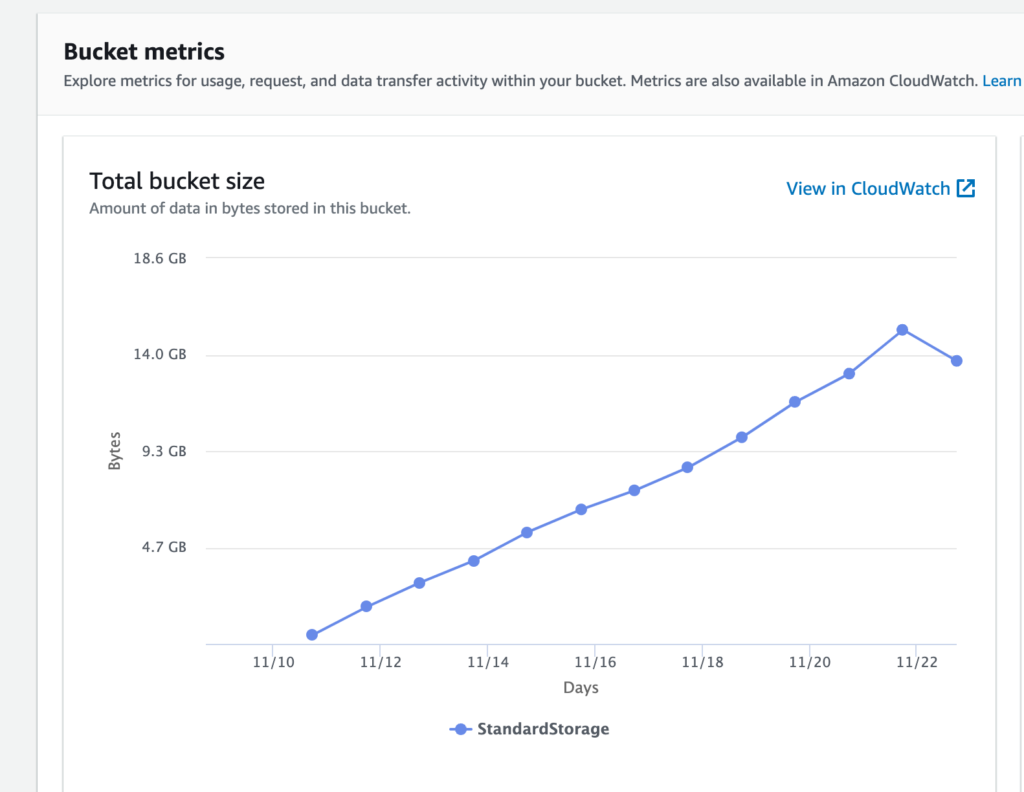
Graph illustrating the growth of media files in Amazon’s S3 for social.ds106.us
That said, the instance is still taking on about a GB of files each day, so file bloat is something to continue to watch and fine tune. I have to believe there’s more we can do given it seems unlikely 30 users are uploading that much media daily, but I could be wrong. This also underscores the point that offloading media to cloud storage should not be optional for instances interested in scaling.
And the final tweak I made was last night when John Johnston discovered that nginx buffers needed to be upped to allow the service brid.gy to use OAuth to link his blog with his Mastodon instance. He did all the heavy lifting of searching for the fix, and I added the following following 3 lines to the http block in /etc/nginx/nginx.conf and it worked.
proxy_buffers 4 16k;
proxy_buffer_size 16k;
proxy_busy_buffers_size 32k;
After saving the file and restarting nginx without errors I got the confirmation from John it worked, which was pretty awesome given how quick and easy it proved to be. I’m not used to that.
So that’s it for the server tweaking thus far, I did upgrade the ds106 instance from version 3.4.2 to 4.0.2, and that went off cleanly. Only issue was me not following the post-migration database instructions, so that was on me. I followed these instructions for my non-docker environment.
The last thing worth sharing is costs in Reclaim Cloud given this has been a question we have gotten from folks, so I am trying to keep an eye on that. I have an 8-day breakdown of costs for my instance that can scale up to 8 GB.
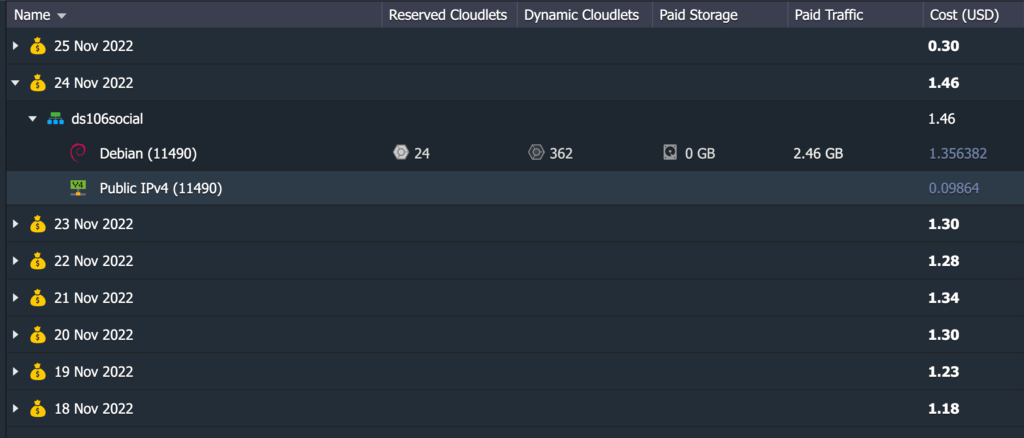
Reclaim Cloud 8-day breakdown of costs for hosting social.ds106.us
So, as you can see from the image above the cost has been increasing daily by a few cents. The cost of the IP address is fixed at .09 cents a day, or $3 a month, the cloudlets (or CPU running the instance) vary daily, and the average has been about 14 per day, which works out to $40 per month in Reclaim Cloud.

Reclaim Cloud environment running the social.ds106.us instance
I’ve read about memory leaks in Sidekiq and wonder if restarting that service every few hours would help. It will be interesting to see how things shake out if ds106 scales. In particular, I am curious if the resources continue to mount for the environment, or if they proportionally taper off despite increased numbers of users. My logical assumption is it’s 1:1, more users more resources, but it seems like a base Mastodon instance without more than one or two users sits around 8 cloudlets, or 1 GB, whereas ds106 has still yet to hit 2 GB for 40 users. Would 100+ users be fine with 4 GB? Not sure, but I’m interested in finding out, so get a Mastodon account on ds106 Social you hippie!

Jim this is great follow-up, follow-on to the examples so far of just getting the Mastodon’s stood up on all four legs (so to speak). The real heavy lifting (which us civilians never realize) is the SCALE. So partitioning out things on a so-called “production service” will be another round of future videos I’m sure. Luckily you got a least a couple test beds and prod instances (.social and rocks) if you need to try out scaling up. Keep it up! I think is one wave you’re on the leading edge of right now. Not seeing tons of YT suggested videos right now with folks demoing/tutorial-ing it up.
I have to say it reminds me a bit of my early work with WPMu, seems like so much is possibly and the idea of open undergirding it means folks might make stuff that will blow your mind and make it a brave new world. Wishful thinking, I’m sure, but I am enjoying it tremendously thus far, and figure the more tools people have to run their own communities, the better to keep the decentralized boat afloat 🙂
Pingback: The Allure of Mastodon | bavatuesdays