
 I’ve been having a lot of fun recently exploring old school technologies as part of The Internet Course I’m teaching alongside Paul Bond. Paul wrote an awesome post a couple of days ago investigating the file-sharing protocol Gopher. I’ve been doing some preliminary investigations into early web authoring initiatives as part of various universities’ online services from the early 1990s onward. There’s some really interesting stuff there, and that will be the focus of a follow-up post sometime this week and hopefully a presentation I give about old school university personal publishing spaces sometime soon. I was planning on talking about this at the Domain Incubator rescheduled for later this week in Atlanta, but I’m sorry to say Tim, Martha, and I won’t be attending because it has been cancelled yet again due to weather. Can you imagine an event cancelled twice in two weeks for winter weather in Atlanta? What are the chances? My heart goes out to David Morgen and Pete Rorbaugh, it really sucks.
I’ve been having a lot of fun recently exploring old school technologies as part of The Internet Course I’m teaching alongside Paul Bond. Paul wrote an awesome post a couple of days ago investigating the file-sharing protocol Gopher. I’ve been doing some preliminary investigations into early web authoring initiatives as part of various universities’ online services from the early 1990s onward. There’s some really interesting stuff there, and that will be the focus of a follow-up post sometime this week and hopefully a presentation I give about old school university personal publishing spaces sometime soon. I was planning on talking about this at the Domain Incubator rescheduled for later this week in Atlanta, but I’m sorry to say Tim, Martha, and I won’t be attending because it has been cancelled yet again due to weather. Can you imagine an event cancelled twice in two weeks for winter weather in Atlanta? What are the chances? My heart goes out to David Morgen and Pete Rorbaugh, it really sucks.
Anyway, this post is a brief look at some of the remarkable primary documents Andy Rush gave me yesterday when he heard me musing about some of those early university web publishing spaces for the community. You see Andy Rush is old gold: he remembers, he was there. What’s more, unlike the rest of us, he saved the paper handouts people gave him about the web from 1994-1997 🙂 And I am oh so glad he did.
The first document I read yesterday was “Entering the World-Wide Web: A Guide To Cyberspace” by Kevin Hughes. Remarkably enough, Kevin Hughes is one of only six World Wide Web Hall of Fame Inductees. He might very well be considered the original edtech pioneer of web technologies having created one of the first campus web sites for Honolulu Community College, including a virtual tour of a campus museum. What’s more, his guide for understanding the World-Wide Web is a fascinating historical and cultural document.

A scan of Andy Rush’s photocopied and stapled version of Kevin Hughes’ “Entering the World-Wide Web: A Guide to Cyberspace”
One of the bits from this guide that struck me right away was from the “How was the Web created?” section wherein it talks about how in 1992 Tim Berners-Lee “continued to speak on and evangelize the project”. Even though it makes total sense that he would have to evangelize the web, at the same time it’s almost bizarre to think that was necessary from our historical vantage point. Just twenty-two years later the web seems so naturalized for us as a cultural artefact.*

Another fact that reinforces Paul’s post about gopher holes was the traffic comparison (in bytes, mind you) between the two protocols between December 1992 and March 1994.
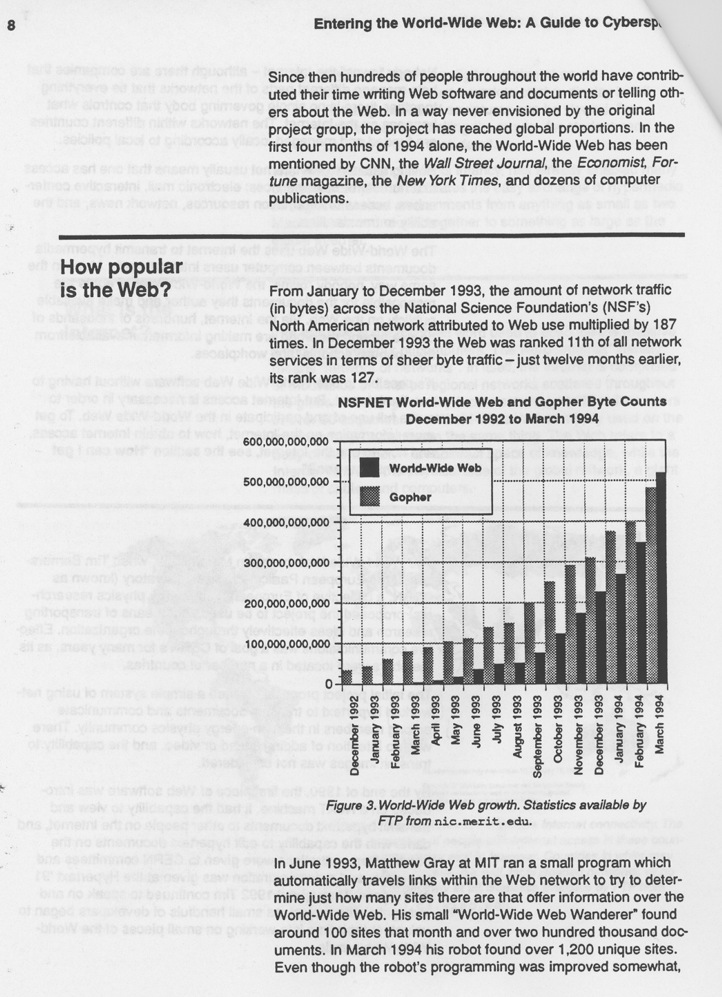
The web came on strong in very little time, although Gopher was only about two or three years old at the time. In May of 1994 Brian Pinkerton of the University of Washington ran his program called “WebCrawler” which found “over 3,800 unique Web sites.” What’s more, Hughes estimates the number of active users of the web around 250,000 to 500,000 in Spring of 1994. Twenty years later and that number is well over two billion? Wild. There is much more goodness in this guide, and I plan on exploring it in more detail over the course of the semester.
Another document Andy gave me was Brendan P. Kehoe’s Zen and the Art of the Internet: A Beginner’s Guide to the Internet.

Kehoe’s guide is crazy because it introduces an internet without the web—IS IT EVEN POSSIBLE!! He provides an overview of a whole range of possibilities from Electronic Mail to Anonymus FTP to Usenet News to Telnet. The section of this guide about Usenet is incredibly funny in that Kehoe can’t hold back his utter disdain for this “news community.” Both of these guides are kinda like how-to zines for the intenret in the early 90s. It’s remarkable how many of these protocols and possibilities before of the emergence of the web have moved into internet oblivion. For example, the archie server was created by….
A group of people at McGill University in Canada….It was originally formed to be a quick and easy way to scan the offerings of the many anonymous FTP sites that are maintained around the world.
….
Currently, archie tracks the contents of over 800 anonymous FTP archive sites containing over a million files stored across the Internet. Collectively, these files represent well over 50 gigabytes of information, with new entries being added daily.
The archie server automatically updates the listing information from each site about once a month. This avoids constantly updating the databases, which could waste network resources, yet ensures that the information on each site’s holdings is reasonably up to date.
This talk about Archie reminded me there was another early search engine for Gopher files (Gopher isn’t even mentioned in Kehoe’s 1992 guide) named Veronica, which I thought was pretty cool in a pop culture kinda way. So Archie searches FTP files and Veronica searches Gopher files, easy enough to remember. D’Arcy Norman turned me onto “early blogging” using the finger protocol (an unfortunate name in many ways) which, unlike Gopher, made it into the Zen and the Art of the Internet guide.
@jimgroom just added a .plan file to my campus account pic.twitter.com/Mu6KKz65GC
— D’Arcy Norman (@dlnorman) February 10, 2014
Another early Unix software that gets mentioned in this guide is Talk, a chat program that was eventually superseded by IRC.
As you probably can tell, I have fallen into a “wormhole” of sorts with all of this, and Im having a blast. Speaking of which, the Zen guide also references some early cultural milestones of the internet, such as the Morris worm created by Robert T. Morris. This was one of the first viruses to be distributed on the internet. And the Zen guide discusses the details, which I’ve heavily excerpted below.
On November 2, 1988, Robert Morris, Jr., a graduate student in Computer Science at Cornell, wrote an experimental, self-replicating, self-propagating program called a worm and injected it into the Internet. He chose to release it from MIT, to disguise the fact that the worm came from Cornell. Morris soon discovered that the program was replicating and reinfecting machines at a much faster rate than he had anticipated—there was a bug. Ultimately, many machines at locations around the country either crashed or became “catatonic.” When Morris realized what was happening, he contacted a friend at Harvard to discuss a solution. Eventually, they sent an anonymous message from Harvard over the network, instructing programmers how to kill the worm and prevent reinfection. However, because the network route was clogged, this message did not get through until it was too late. Computers were affected at many sites, including universities, military sites, and medical research facilities. The estimated cost of dealing with the worm at each installation ranged from $200 to more than $53,000.
So awesome, and this is just the beginning of my travels through various moments of what I hope becomes a class that evolves into a broader cultural history of the internet. It’s five weeks into the first semester of teaching the class now, and I am starting to get visions of what the Internet Course might be.
__________________________________________________
*One thing to keep in mind is that the online version of the “Entering the World-Wide Web: A Guide To Cyberspace” only contains two sentences in about “How the web was created?” versus the four paragraphs in the May 20th, 1994 version of the printed guide Andy gave me. Not sure if there are other versions on the web, but this is a heads up to that discrepancy.

You are an oral historian, my friend.
You and Andy got my combing through my old files, I have a fair but of stuff from 1994-1996 on the early web stuff at Maricopa. I commented on Paul’s post, but I wrote a short article in our center’s publication about Gopher in Feb 1993, a few screen shots
http://mcli.cogdogblog.com/labyforum/Feb93/Feb93L7.html
I’m starting to repost a lot of ym old sites; the Labyrinth-Forum was a print thing I also put up in HTML
http://mcli.cogdogblog.com/labyforum/
One of the early web references was John December’s “The World Wide Web Unleashed” first edition October 1994 I believe (still for sale on Amazon). I got a free copy because he included one of my early web sites– it was a directory listing of community college web servers. I don’t have the book, but a xerox of his autograph and my article.
And there was a 1996 of a magazine call “The Net” which referenced the HTML tutorial — how proud that my site was included in the issue where the cover feature was “Sex Online” (which I have, looks like it is still in cellephane) http://cogdogblog.com/2012/01/21/web-as-it-was/ I have a few other web magazines from 1995-1996
One of the first web crawlers I remember was MomSpider, a references said it was first coded in 1993 http://www.robotstxt.org/db/momspider.html
This is fun. I’m looking for some stuff to scan.
Pingback: Old Gold Days at Maricopa - CogDogBlog
Pingback: Innovation Lost | bavatuesdays
Pingback: Old Gold Days at Maricopa – CogDogBlog