
I’ve been on a bit of an offloading kick these last months, and I’m digging the idea of controlling server environment bloat by having media hosted in an S3 storage situation. It simplifies cloning, updating, and/or migrating a server environment, and often times results in faster load times. I’ve been doing it with bigger WordPress sites for months now, and it’s high time to turn my attention to some other applications, in this case the web radio software Azuracast.

More than 3 years ago ds106radio was migrated from Airtime to Azuracast. It was the right move, and Azuracast has proven to be the best in the business, I love it. Buster Neece, the primary developer of Azuracast, has made a big push the last several years to containerize the software, making it much easier to host. Updating Azuracast is now a piece of cake, and new features just keep on coming. One feature that’s been around for a while that I’ve yet to take advantage of is offloading media, and given the instance has surpassed 100GB of live broadcast recordings, it’s officially overdue. I realized the value of offloading media after hosting Mastodon for a year, social.ds106.us has 168GB of offloaded media, and that’s for a very small server. Offloading at just $5 a month for up to 250 GB on Digital Ocean’s Spaces is a total deal, and it frees up significant space on Reclaim Cloud.
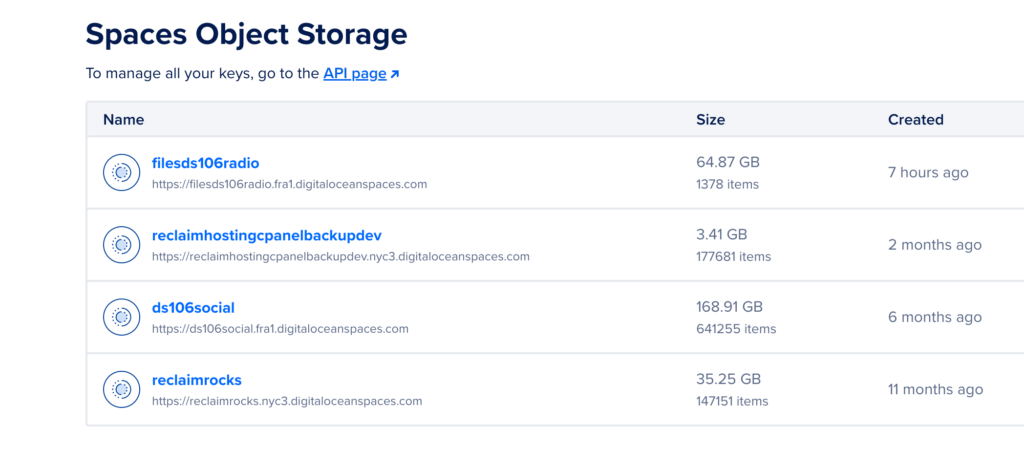
A few of our S3 buckets in Digital Ocean’s Spaces
So, below are details of how I offloaded all media, backups, and recordings on the mighty ds106rad.io to Digital Ocean’s S3-compatible object storage Spaces. You can find a quick-start guide for getting a bucket up and running on DO’s Spaces. Apart from that, I installed the handy, dandy s3cmd tool on the Azuracast server to help with moving files to S3. I also recommend installing NCDU on your environment to see where all the larger files live (this could have saved me some hassle if I installed in sooner).
When working in Reclaim Cloud, I do all my testing on a clone of the production site that I spin up to make sure no changes I make break the live site. If all works as planned I do the same thing on production. One could also just as easily destroy the production server and point DNS to the clone where all the changes were made successfully, but I am superstitious and inefficient so I do everything twice.
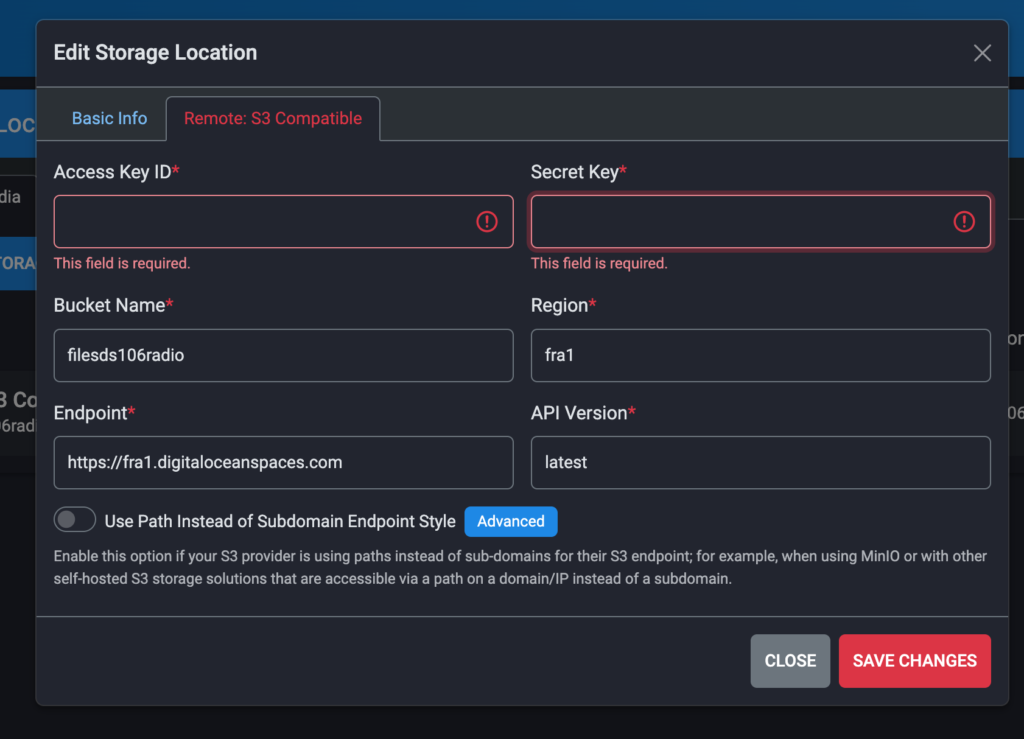
When configuring s3cmd (s3cmd --configure)you will need your bucket access key, secret key, region, endpoint, and bucket name. Something like this:
Access Key: <your S3 access key>
Secret key: <Your s3 secret key>
Region (my region for Spaces is frankfurt): fra1
bucket: filesds106radfio
endpoint: fra1.digitaloceanspaces.com
The above format worked for me on DO’s Spaces (you will need your own access keys), and thereafter the server will automatically connect to the S3 bucket, which is convenient. Beyond that, it is time to locate the files and start offloading them to S3. Here is where I should have used the ncdu command sooner, given it’s a handy command line tool that lets you know how much space is being used in each directory, allowing you the ability to drill down by directory. So, if I’m trying to figure out where the 100GB of recordings are stored on the server, I could track it down with this command. But I did things the hard way, I essentially used a command I had learned from my colleague Taylor to remote login to the container within the server environment to copy all the files out of the container into the broader server environment.
I know, it’s confusing, but that’s part of wrapping your head around working with containers. Each container can be logged into separately using the command docker exec -it containerid sh -this will allow you to move around in the Alpine linux container and use a few, very limited commands. For example, s3cmd does not run within the specific containers. So I got the brilliant idea of copying the media, backups, and recordings directories from the container to the docker environment so I could then use s3cmd to put them in the S3 bucket. You following? Probably not, but think of it like this, the server environment is a container running a Docker Engine environment that can harness all the tools and commands of CentOS 7, whereas the specific container running Azuracast is packaged as an Alpine Linux container with far fewer server bells and whistles and only limited packages and command line affordances. Containers within containers, and the simplification of the container envrionments within the Docker environment make them run more efficiently.
Here is the command I used to copy files from the Azuracast container into the general server environment:
docker cp containerid:/var/azuracast/stations/ds106radio/recordings /var/azuracast/
I was stoked that this worked, and all the files from /var/azuracast/stations/ds106radio/recordings could be copied out of the container and into /var/azuracast so that I could then run the following command to put everything I just copied into the S3 bucket:
s3cmd put /var/azuracast/recordings/* s3://filesds106radio --acl-public --recursive
That worked, but when I had finished the process and was deleting the media on the server I offloaded, I fired up the NCDU tool to find any larger files. It’s then I realized all the media was in /var/lib/docker/volume/azuracast_station_data/_data/ds106radio/recordings and I did not need to remote ssh into the container and copy everything, I could much more easily have run s3cmd from that directory to offload media. Nothing like learning that after the fact, but working through this conceptually has helps me understand how containers operate, which is very useful–despite all the extra work.
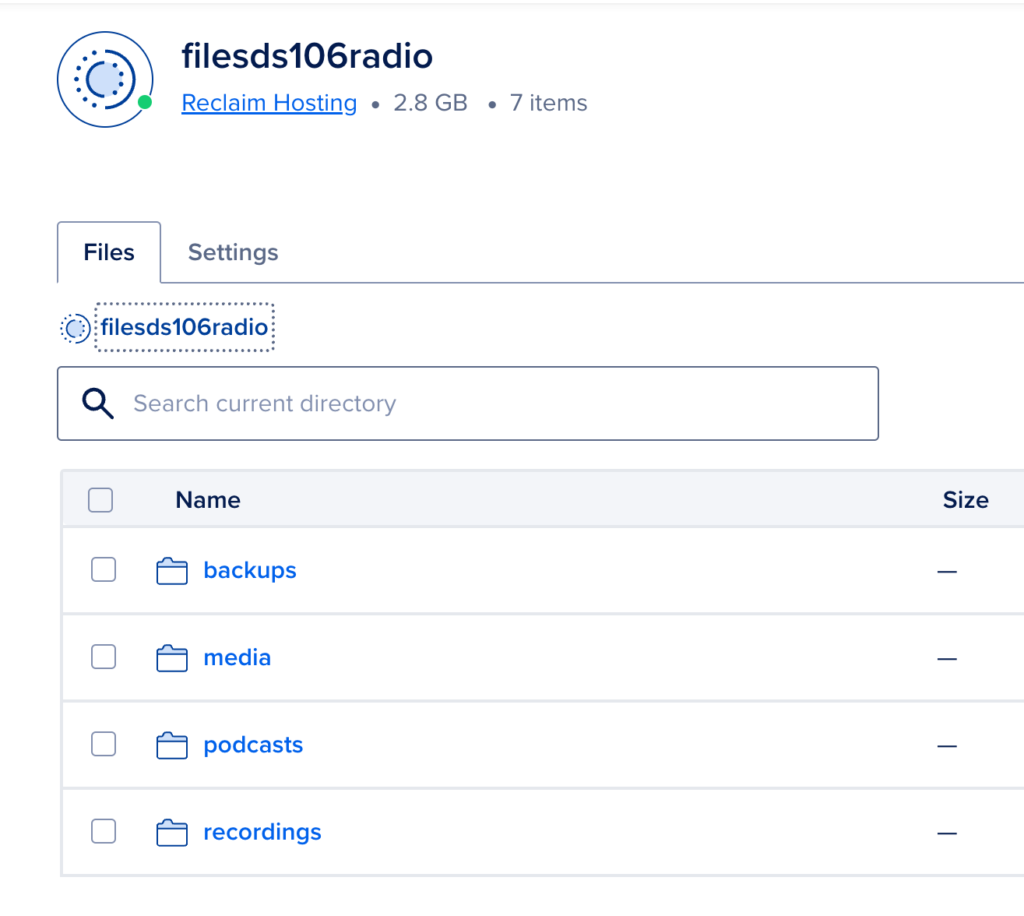
S3 Bucket with directories for backups, media, podcasts, and recordings
Once all the data was moved to the Spaces bucket, I then needed to login to Azuracast and update the storage locations to point to S3 for media, recordings, podcasts, and backups.
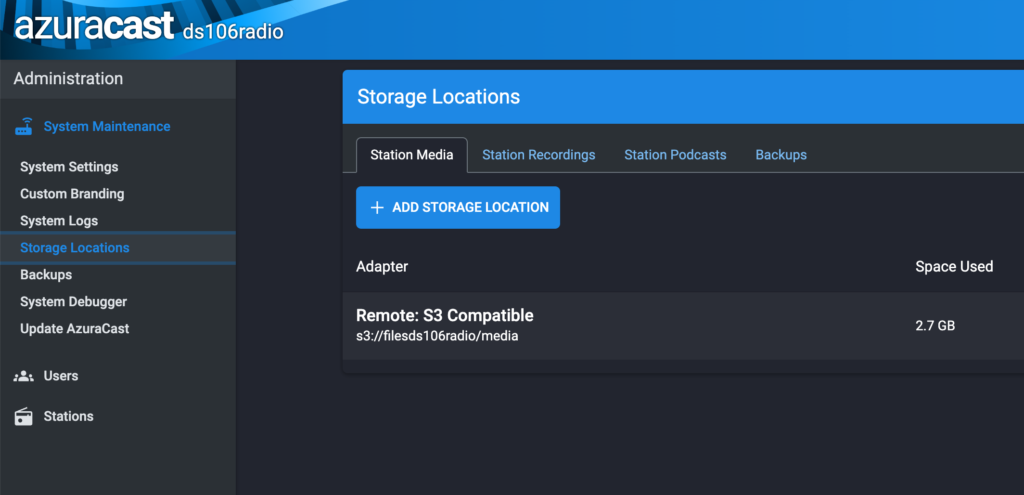
In System Maintenance–>Storage locations you can add the new S3 storage location using much of the same data referenced above for setting up s3cmd.
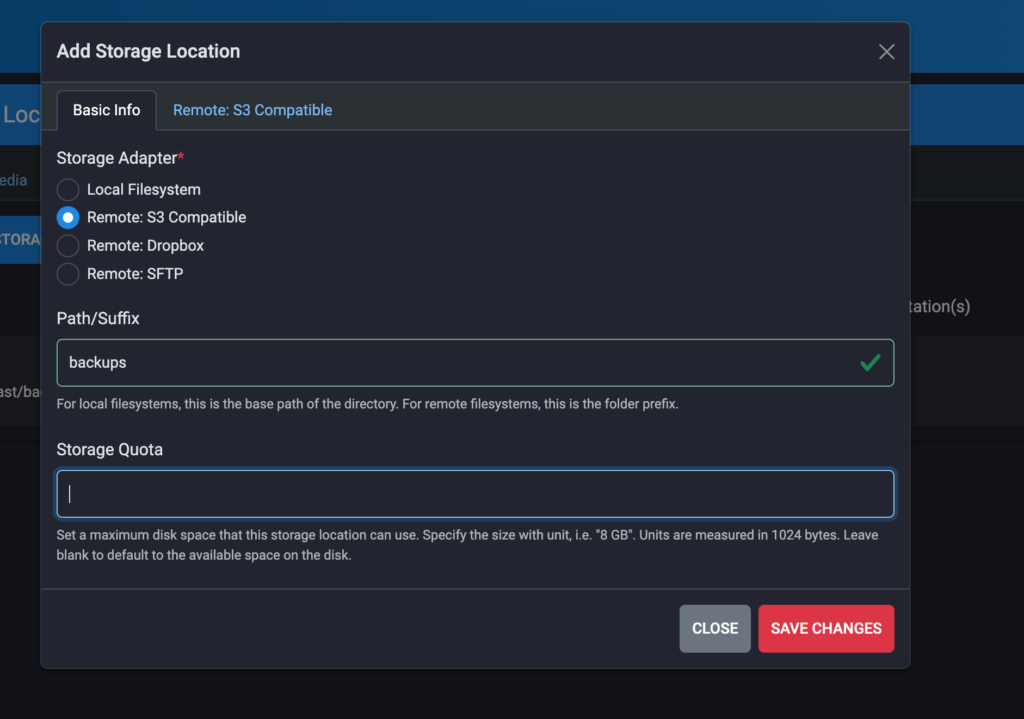
Once you add the bucket data for each type of media (having some way to carry the S3 details over for each storage type would make it easier/quicker) you’ll be asked to update your server configuration with a quick reboot, and the media will start offloading immediately. Given we’ve already copied pre-existing media to those buckets, the broadcasts and media archive will be already be populated with old recordings and previously uploaded media.
With that, you can remove all the media files on the server and save yourself well over 100GB of space.

Pingback: Offloading Peertube Media to S3 | bavatuesdays
Thanks for this article. I just started using AzuraCast and I already know my local storage will fill up quickly on my VPS. Currently testing one of my stations with iDrive S3 storage for a few days before committing. Quick question if you might know the answer… AutoDJ will fetch tracks from S3 and cache them. Do you know how much data gets cached on localhost and, I’m assuming, it gets automatically deleted after the track has streamed?
Johnny,
That is a very good question, and to be honest I am not sure. I would ask over at the Azuracast Discord community, they are quite helpful, and are much, much smarter than me! Glad this might have helped, and sorry my knowledge is a bit limited when it comes to caching
Thanks for the reply! I was just going to write a follow-up to my question, as I have the answer now. I setup a test station and have been monitoring the file management. The AutoDJ will fetch the currently playing media file from S3 and also the next two files in the queue. They are stored in /var/lib/docker/volumes/azuracast_station_data/_data//media/temp directory. It will only keep 2 files cached, purging old when it fetches next file from S3!
That is pretty awesome, and thanks for closing the loop here. I have to say Azuracast is pretty awesome piece of open source software