
Many of us in a certain subgenre of edtech have been working for a long time to try and use RSS to syndicate and aggregate posts from individual blogs into community sites. These sites are sometimes referred to as planet sites, mother blogs, aggregator sites, syndication hubs, etc. A good example of this is ds106, where posts are not only syndicated into the Blog Flow, but also the assignment bank—making for a richer, more targeted contextualization of student posts. Over the last seven years ds106 has syndicated more the 75,000 posts, providing a point of creative contact—if you will.
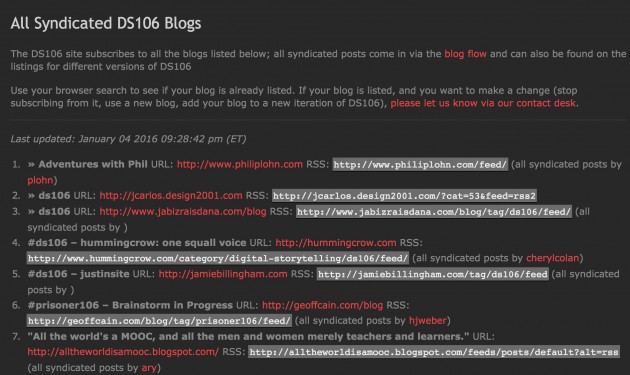
The syndication and aggregation for ds106 is all handled by FeedWordPress, which can grab the RSS feed of just about any publishing platform that exposes one. In order to simplify things, we’re using a Gravity Form to help automate the sign-up process. It’s far from a perfect setup, but it has been working fairly well for almost seven years now. In fact, it has been a template for other site aggregators, including the first Community directory site that Martha Burtis and Tim Owens built around UMW Domains in 2014 (which is no longer in use).
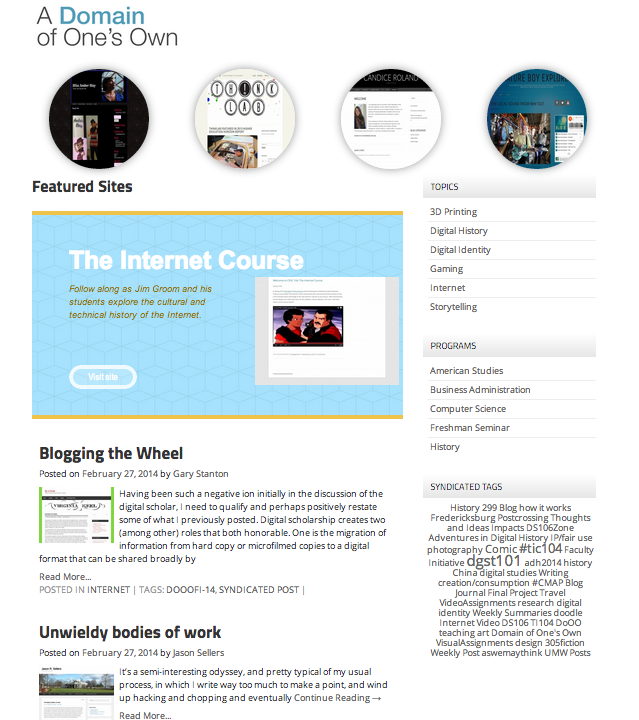
This community site for UMW Domains did a number of things: it aggregated recent posts, enabled a filtered view of posts by instructor, department, course, semester, software, etc., as well as providing a calendar view of posts. It was actually very awesome, and you can read about it in more detail here. That said, much of the ability to filter posts and add metadata was hacked together with FeedWordPress, Installatron, Google Spreadsheets, and a fair amount of duct tape. And while it worked—it was not easy to share. In fact, we tried as much with Emory University and University of Oklahoma, but it was not something easily supported given its idiosyncrasies. What’s more, as staff changed at UMW’s DTLT it was increasingly less sustainable (and eventually retired) with Martha running the Digital Knowledge Center and Tim going full time at Reclaim. But in the end it was a solid proof-of-concept, and one we were keen on returning to in earnest when time and energy allowed.
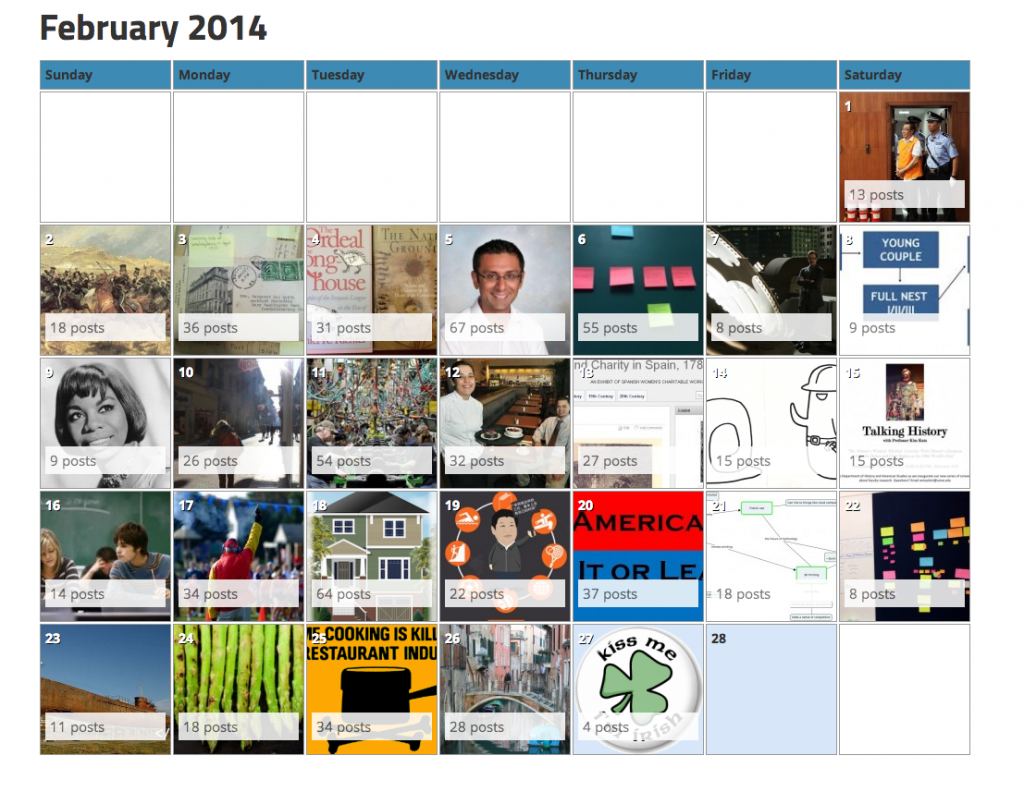
Martha built a feature that provided a calendar view of all the posts on UMW Domains -so cool.
Since then we’ve had a number of schools running Domain of One’s Own express interest in some version of UMW’s prototype. A few schools were willing to fund the work, but we just didn’t have the time. I think one of our strengths these last couple of years has been knowing when to pass on work. As much as we wanted to focus on building Community Directories given their potential to showcase work happening at various institutions, we knew it was too much. I think the fact we did turn the work down made our hosting that much better, but the community sites remained a stream deferred.

A Stream Deferred
We did try working with a developer to build aggregation hubs for Davidson and BYU using Known, but those did not pan out. After that BYU went ahead and started developing its own community directory. The site reproduces much of what Martha and Tim did in 2014, as well as integrating with BYU’s homegrown students information system to automatically de-provision inactive student sites It promises to be an excellent tool for showing off all the great domains work at BYU, as well as illustrating the folks at BYU are doing some deeper integrations to get associated metadata like user status (student, staff, faculty), graduation date, major, etc. I’ll definitely be blogging the work they are doing in more detail once it goes live.
But this brings me to the original point of this post—that took some time now didn’t it? I do apologize for rambling, but a little context helps when writing these posts given aggregation hubs are a topic I’ve been going on about for near on a decade. Anyway, this Spring Reclaim was finally in a position to return to the Community Directories, and we reached out to Marie Selvanadin and Yianna Vovides at Georgetown (who were keen on exploring this work back in 2015) about trying to build a Community Directory site from scratch. We also reached out to Tom Woodward to lead the development given his work with APIs of all kinds, The idea was that rather than doing this using FeedWordPress, we would try and build this using WordPress’s API. This was new territory for community aggregation hubs, and luckily Marie and Yianna were more than willing to approach this as an iterative experiment.
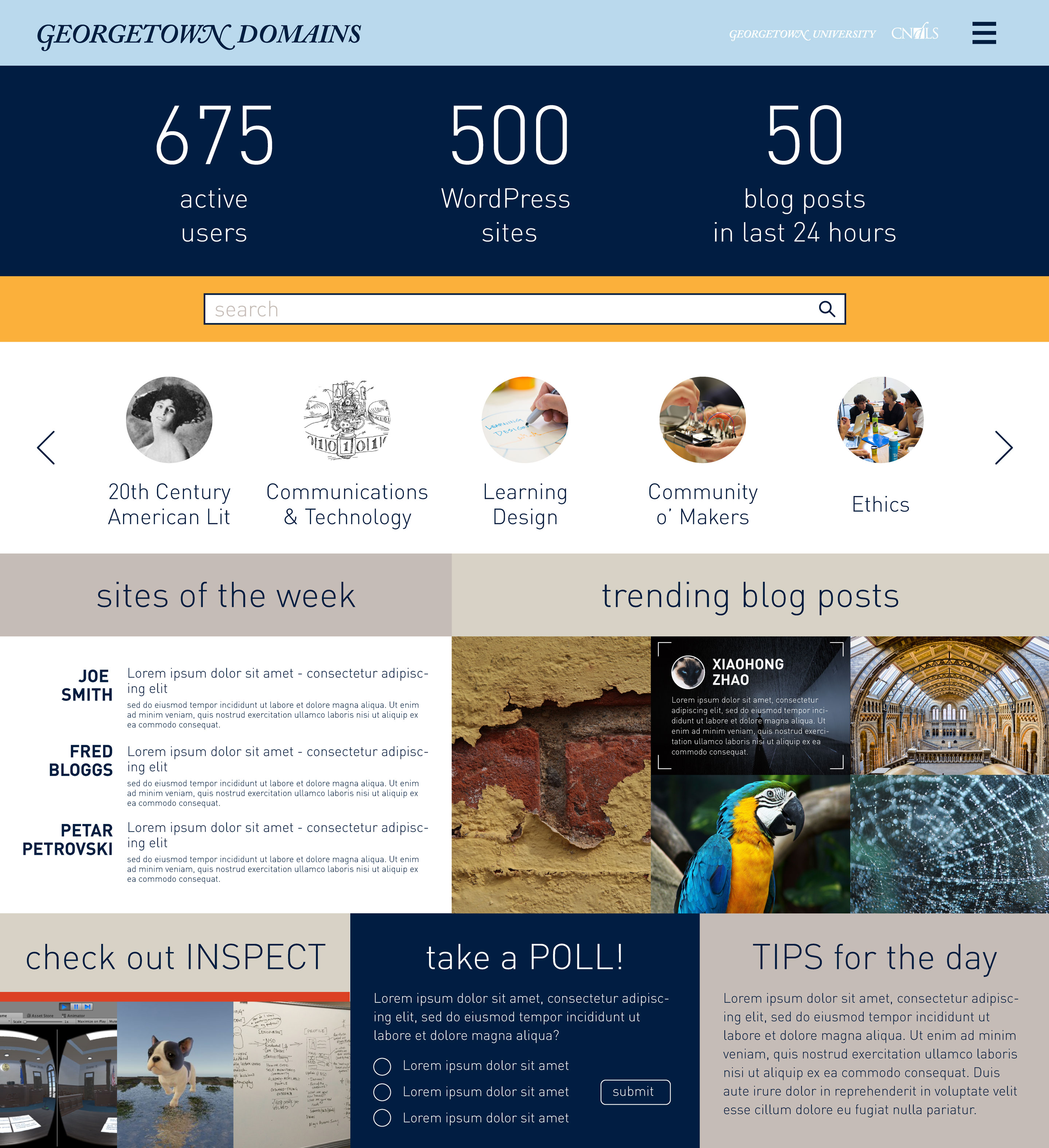
Georgetown Community Site Mockups
So, the development starts in earnest during the Spring and the initial work was presented at Domains 17. You can get a good sense of how Georgetown was approaching this site from the post “Envisioning a community site for GU Domains” Marie published back in June:
The presentation itself was a culmination of a few weeks of ideation, designing and prototyping with the team for this phase. Prior to this, we have always been intrigued by the idea of a true community space where people can create, collaborate and discover each other …. We conceived this community model in 3 layers – the macro layer which in this case at the campus level, the next layer is geared towards micro/sub communities which could be program level websites and the third layer is the individual layer.
I really like this vision of the community site as multi-level reflecting several visions of the university. From the macro to the individual:

Soon after Marie posted how Georgetown was imagining their community site, Tom posted more details on how he was building the site in his post “Community- Technically Speaking.” In this post he not only discusses the various reasons community sites may or may not work, but gives a look into how he is building the community site. By using the WordPress API he can grab recent posts (and pages) from a list of WordPress sites* as well as filtering out Hello World posts, and then store them in a Google Spreadsheet. He also details how he uses phantomjs ( or “a web browser without a graphical user interface“) to capture screenshots of all aggregated sites and then uses Vue (a framework for building the GUI phantomjs doesn’t provide) to combine the spreadsheet data with a screenshot and then represent it as a directory listing on a web page. It would look something like this: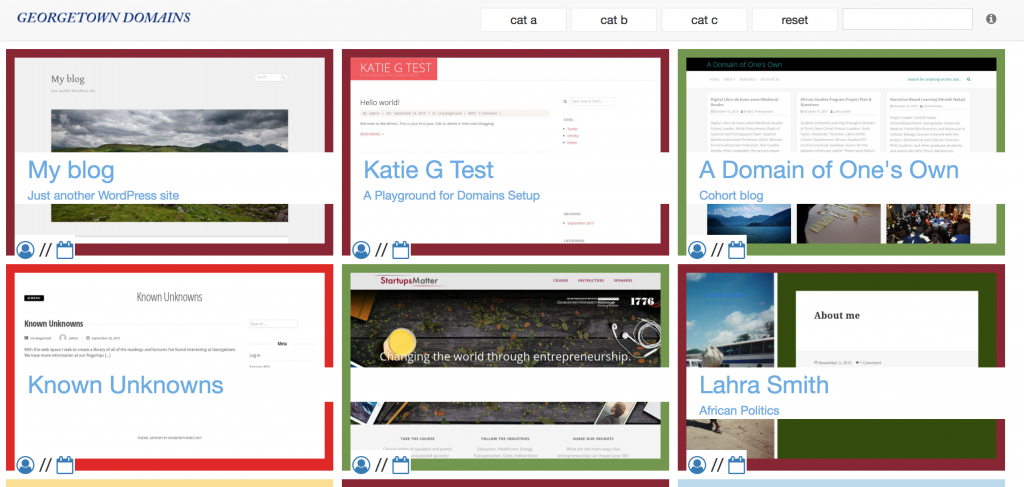
In the above example we have Tom’s first iteration on Georgetown’s vision, which has screenshots of all the WordPress sites as well as a link to individual posts as a list and/or a timeline. The different categories can be associated with a program, course, theme, etc. Associating tags can be added at the point of installation through our script installer (Installatron), or through a plugin in WordPress that’s automatically added and activated at the point of setup. What’s interesting is none of what you see above is happening through WordPress, Tom is accessing public content from a large list of WordPress sites through the API and pulling it into a Google Spreadsheet. He is also using Phantomjs to grab screenshots and then mashes that up with the data in a webpage using VUE. I think I finally understand what Kin Lane might mean when he refers to a “headless CMS” using Google Apps, Github, etc. That said, this whole directory still assumes folks are using WordPress—which probably defeats the point.
What’s more, Tom re-did much of this same functionality from within WordPress. Watch the above minute and a half screencast which takes you through the latest iteration of how you can essentially add a URL of any site and it will quickly capture a snapshot, including a list of available posts and pages, as well as data around number of posts, pages, last updates, etc. And this is just one way to add them, you can have folks use categories on their sites, a form, provide options for opting in (or out) at sign-up, etc. This is exciting work, and by doing it through WordPress like this it can be packaged into a plugin that folks can use on their Domains sites—or even for WordPress Multisite installs. Think about the innumerable use cases there. You can get a look at what this might look like at the macro level here.
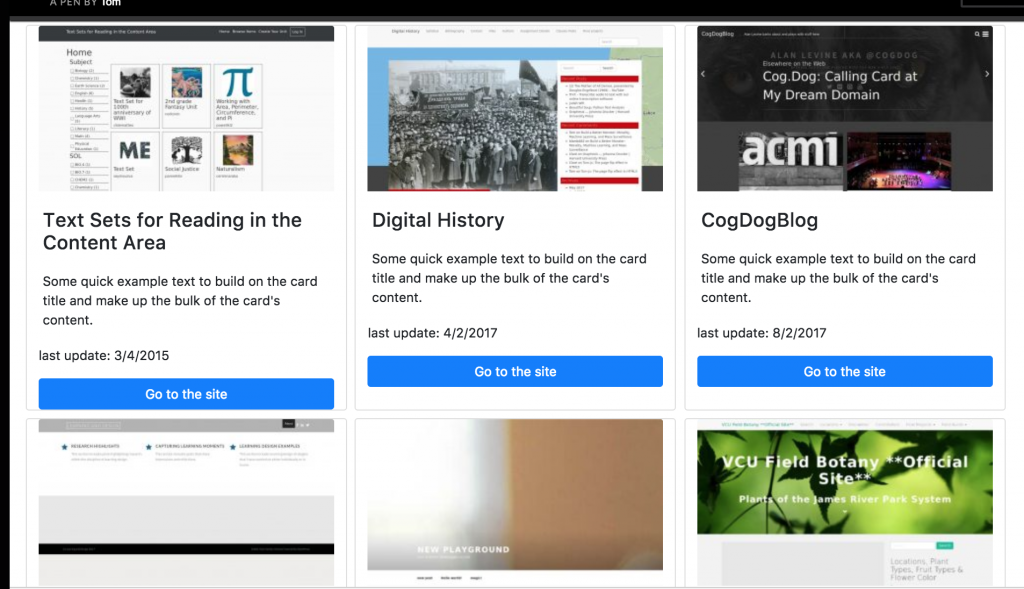
Keep in mind all this is yet to be styled, but the screenshots Georgetown shared would be one way the directories could look. We are still somewhat at the raw data aggregation and exposition stage here. The in-process status also includes questions around what data to collect and why. Everything collected here is already on the open web, but in the various discussions we have had the ability to opt-out of any centralized directory must be front and center. What’s more, the ability for the data to go away must also be an option, so resisting the inclination to archive posts as been painfully counter-intuitive for me—this was often the default for how we aggregated ds106 posts.
There is still much to be discussed on the data collection front, and it is important to note none of this would have been possible without Georgetown’s willingness to support the exploration of what’s possible. Additionally, Davidson College saw the cool work Marie, Yianna, and Tom were doing at Domains17 and are now working with Tom to revisit their earlier attempts at trying to create a community hub (more on their work in another post). Having willing partners in the process is crucial, and it is one of the many reasons we did not rush it and started from scratch. It’s important to remember that without folks like Marie and Yianna on-the-ground at these institutions who have specific vision for various use cases concomitant with myriad concerns this whole thing becomes just another generically packaged edtech portal/portfolio product entirely removed from what makes sense. This might be the best reason to wait until we have the time, energy, and willing partners and developers to make something so many of us have been approximating for well over a decade.
*For example, this list can be provided from Installatron for a school that is using a Domain of One’s Own server.

I’d love to give the solvonauts engine a whirl as an aggregator (as it does flickr, twitter, instagram, slideshare etc) so can do aggregates on lots of areas