

Marx and Engels lego photo used courtesy of Dunechaser
So I’m finally returning to creating a discussion framework for the Reading Capital site. I will detail my thinking for the design of the site below (and in at least two subsequent posts), and I invite any and all recommendations and criticisms. It’s a model that is far from perfect, but provides an opportunity to look at how we might provide a platform for aggregating and re-presenting posts and discussions in a distributed manner.
For the technical details behind this setup go here for more information.
Section 1: Blogging
I am going to begin with blogs because I think they provide a powerful tool for conducting a discussion that allows for filtered feeds, more precise aggregation, little or no publishing overhead, and individual “ownership” of the original posts for archival posterity. More than that, it allows one to compose and publish their work from their own space, while at the same time pushing it out to a site like Reading Capital where others might see it, follow the link back to the original site, and engage in conversation on the author’s blog and beyond. Blogging is, at its core, a way of making connections around ideas, and what’s more it provides each person with their own space to feature, control, and share their work on a range of subjects.
So, how does blogging work in Reading Capital? Well, quite simply actually. If you have your own blog then you’ll just share your feed for aggregation (more on this in the next sections). If you don’t have a blog you have a host of free options. You can get a blog with WordPress.com, Blogger, TypePad, or even from the Reading Capital site itself (which is being run on WordPress Multi-User).
Note: a quick word on blogging platforms that I would love some input on, it is my experience that WordPress.com (based on WPMu) are the only large, commercial services that allow for feeds on categories and tags out of the box. Am I wrong with this? If not, then I highly recommend you get a blog on WordPress.com so that you get filter your site’s content using category and/or tag feeds (more on why and how to do this shortly).
Section 2: Adding and Filtering Feeds
So, once you have your own blog and you start writing and linking to things, discovering YouTube embed, the beauty of Flickr photos, and all kinds of other fun stuff that has nothing to do with your reading of Marx’s Capital, you are going to need a mechanism for filtering only certain content from your blog to the Reading Capital site. Here is how you do this with your own WordPress blog, a WordPress.com blog, or a blog you get on Reading Capital.
*Filtering content by category
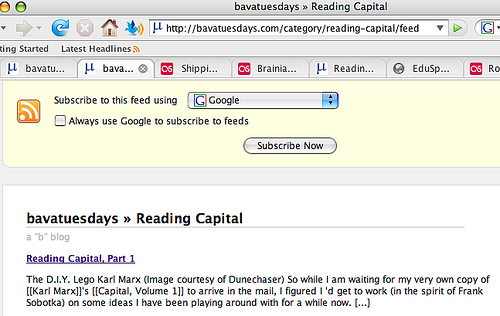
Filtering content by category is fairly straightforward. All you need to do is place the posts you want to filter out accordingly to a specific category, and then grab the feed for that category. For example, if I wanted to feed my posts about my reading capital from bavatuesdays out to the Reading Capital site, which I will, then I would just need to create a category called Reading Capital and put all my posts about this subject in that category. Then grab the feed which will look like this:
http://bavatuesdays.com/category/reading-capital/feed
*Filtering content by tag
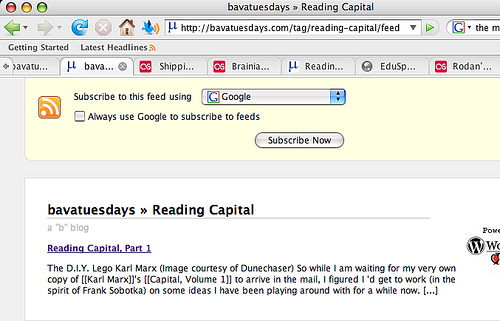
If you don’t want to create a separate category, that’s fine, just tag all your posts that have your readings with a consistent and unique term. For example, I will be tagging my posts that have my reading with “reading-capital” (no quotes in the tag), the feed for which will look like this:
http://bavatuesdays.com/tag/reading-capital/feed
Section 3: Aggregation of Content to the Reading Capital Site
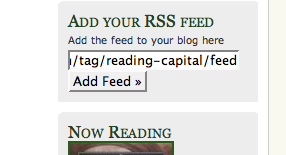 The aggregation of people’s content from where ever they are blogging into the Reading Capital site is the ultimate goal. This is accomplished pretty easily (if you want the technical details go to this post) with the “Add RSS” field in the sidebar of the Reading Capital site. All you need to do is add the filtered feed for you blog that we detailed above, and the relevant posts from your blog with be republished on the site.
The aggregation of people’s content from where ever they are blogging into the Reading Capital site is the ultimate goal. This is accomplished pretty easily (if you want the technical details go to this post) with the “Add RSS” field in the sidebar of the Reading Capital site. All you need to do is add the filtered feed for you blog that we detailed above, and the relevant posts from your blog with be republished on the site.
There are a couple of useful things about this setup. First, the post title (also known as the permalink) actually links back to original post on the author’s site. Second, comments are closed on the re-published post so that people will go to the respective post and comment there, keeping in logic with the distributed logic of blogs. Third, the entire posts are republished on reading capital so that it provides an aggregator for all relevant posts that anyone can subscribe to (http://readingcapital.org/feed), browse, or search.
We already have a useful example that may clarify a few things. Jack Stephens of The Mustard Seed fame has included the feed for his WordPress.com blog. By including the feed for his whole site (http://themustardseed.wordpress.com/feed) all of his content will show up on Reading Capital. Now if he were to create a category and/or tag titled readingcapital, or whatever he likes, and then tag or categorize the relevant poss according after adding the new feed to the sidebar —which would look something like this http://themustardseed.wordpress.com/category/reading-capital/feed—then only the relevant posts would be re-published, allowing for filtered content for very specific tags or categories. Pretty cool, no?

Filtering a feed on Blogspot.com is also easy. Here’s the format:
A search on a label in Blogspot generates this URL:
http://xxx.blogspot.com/search/label/labelname
To filter a feed, just replace “/search/label” with “/feeds/posts/default/-/” like this:
http://xxx.blogspot.com/feeds/posts/default/-/labelname
That’s it.
Source:http://labnol.blogspot.com/2007/08/offer-rss-feeds-for-blogger-search.html
Pingback: Reading Capital: a Long Overdue Postmortem | bavatuesdays
Pingback: What was Eduglu | bavatuesdays