BYU’s Bold Plan to Give Students Control of Their Data
I was really pleased with Marguerite McNeal‘s article in edSurge on Brigham Young University’s Personal API experiment. It can be hard to explain (at least for me), but she does an excellent job providing an accessible frame for the project by looking at it in terms of students finally being able to manage and control their own data. I think the following paragraph summarizes the idea behind a personal API as clearly as anything else I’ve seen:
A personal API builds on the domain concept—students store information on their site, whether it’s class assignments, financial aid information or personal blogs, and then decide how they want to share that data with other applications and services. The idea is to give students autonomy in how they develop and manage their digital identities at the university and well into their professional lives
The idea of autonomy in relationship to our personal data puts the discussion in a far broader context, and its immediacy is anything but academic. That said, I think it’s telling that a number of universities have been pushing hard to bring the importance of controlling your data to their academic communities. BYU’s work around the personal API is a really exciting early attempt at what this might look like. I could listen all day to Phil Windley talk about what he calls “sovereign source identity,” an idea he credits to fellow Long Islander and UMW grad (we met at UMW though) Devon Loffreto:
“We want to teach students that this isn’t the only way identity happens online. They can create their own,” Windley says. This fall BYU introduced its Domain of One’s Own pilot to 1,000 student and faculty participants. But offering personal Web spaces is just the beginning, Windley says. “Domains help students understand their personal identity. The next step is understanding your personal data and how you control that.”
Absolutely right! And Adam Croom—who has been going gang busters with University of Oklahoma’s Domain of One’s Own project OU Create—frames this argument along the lines of a negotiation that should be taking place but isn’t:
“It’s the idea that tapping into one’s data should be a negotiation that the student gets to make,” says Adam Croom, director of digital learning at the Center for Teaching Excellence at the University of Oklahoma (OU). “Why can’t I manage what apps tap into my data, whether that’s the learning management system or the bursar’s office? Why aren’t there terms and conditions for students to understand who has access to their data?”
Another article I found alongside this one, thanks to the Cassandra of Ed-Tech*, was the article in Education Week proclaiming 2016 will be “The Year of Agency.” If that’s right—and I hope it is—that means more an more universities will need to start rethinking their infrastructure, and APIs have helped BYU and University of Oklahoma do just that. And so much of that work has been make possible thanks to the tireless evangelism of Kin Lane who has provided a vision of what APIs can be for Higher Ed. One we desperately needed.
At the same time, giving students, faculty, and staff more control over their data will not be without some serious struggle. A response to this article published today on EducationDive illustrates why giving students control over their data might be an issue for some:
Schools are tracking student movements around campuses, incorporating data about how many times they visit the library or the tutoring center into performance data, merging that with student information system and learning management system data, and then developing predictive models to help counselors and students themselves. Giving students access to their own data is one thing, but letting them block others from seeing it is a different beast that could derail retention efforts.
Derailing retention? It’s strange to see the idea of allowing students to decide who gets to see their data, for how long, and why as somehow antithetical to keeping them? There is a joke in there somewhere. Fact is, the realities behind the learning analytics applications that have been relentlessly tracking student’s personal data may very soon be coming to a head. I would bet there has been little to no transparency about what student data universities are tracking, and whom they are sharing it with. Hell, I’m sure a number of universities aren’t even aware themselves of what data these third party applications are collecting. The idea that someone empowering students to opt-out of these unilateral relationships with various technology vendors is somehow preventing them from doing their job is demonstrative of just how much of the job of teaching and learning they’re offshoring to third-party technology solutions. And I won’t even get into the insane idea that tracking a student’s movement around campus is a sound academic counseling strategy.
Reclaim Hosting was born out of a movement that is grounded in the principle of empowering students and faculty to take control of their teaching and learning. And as Phil Windley notes, understanding who has access to their data and how it is being used will be ground zero for that struggle if we are, indeed, entering the year of agency.
_______________________
*I found this article thanks to the all-knowing, all-seeing Audrey Watters, who linked to it in this week’s Newsletter. You’d think given I was quoted in this I might know about it, but Audrey actually reads the web—all of it—unlike me 🙂



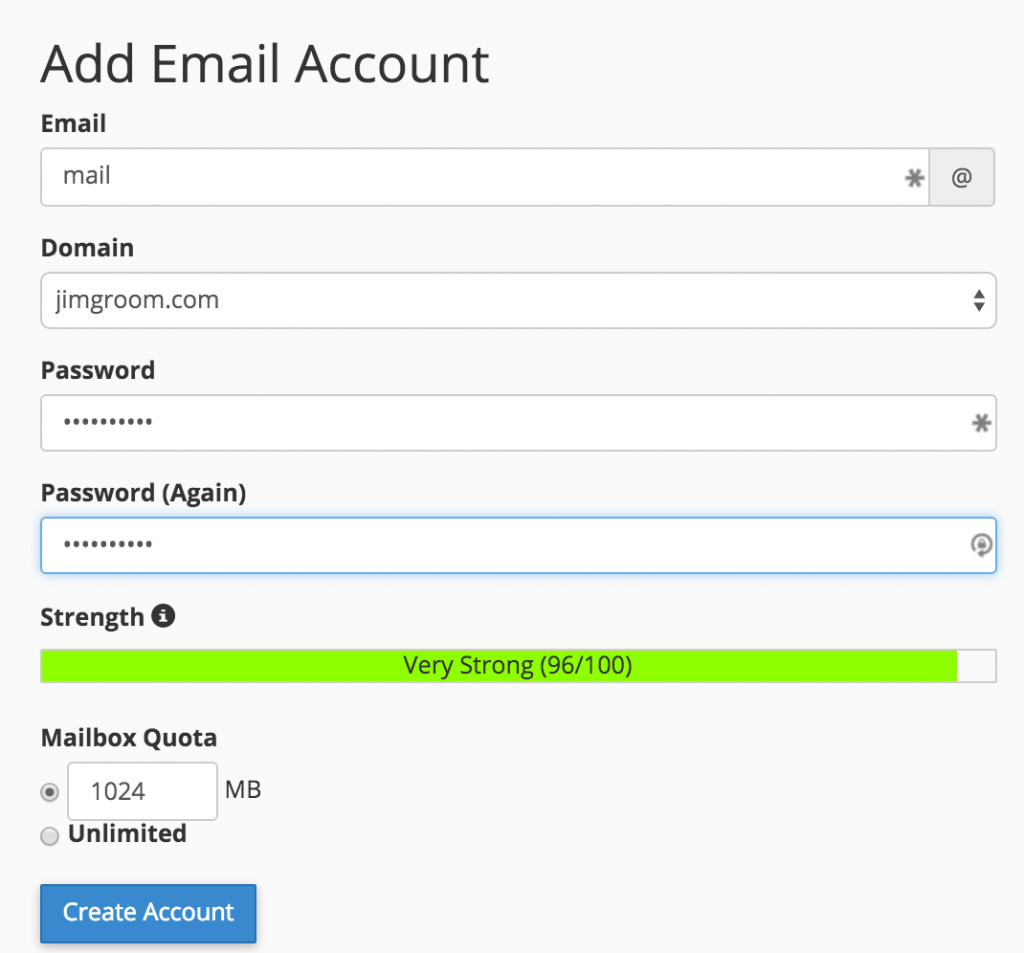
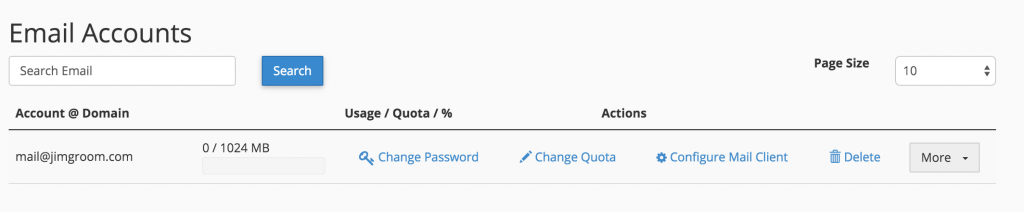
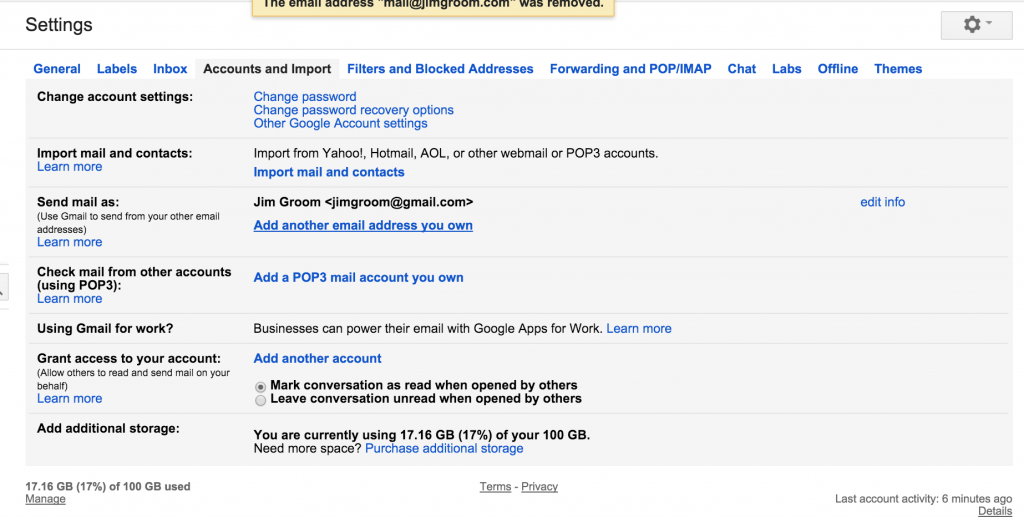
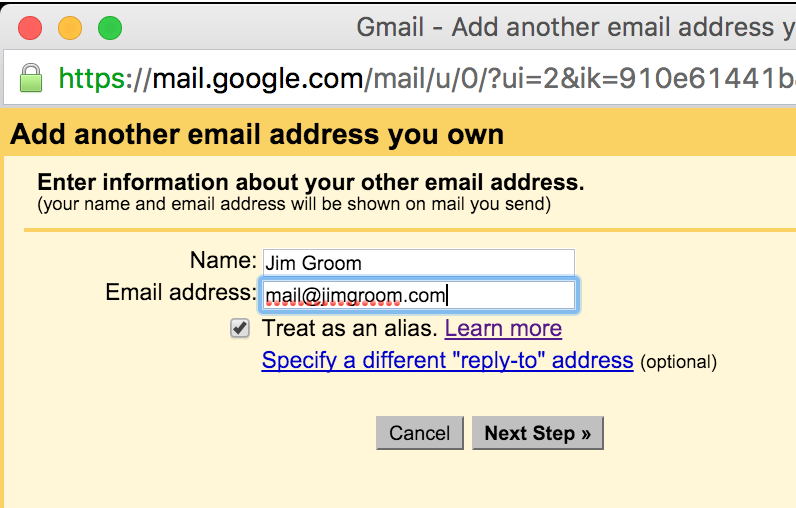
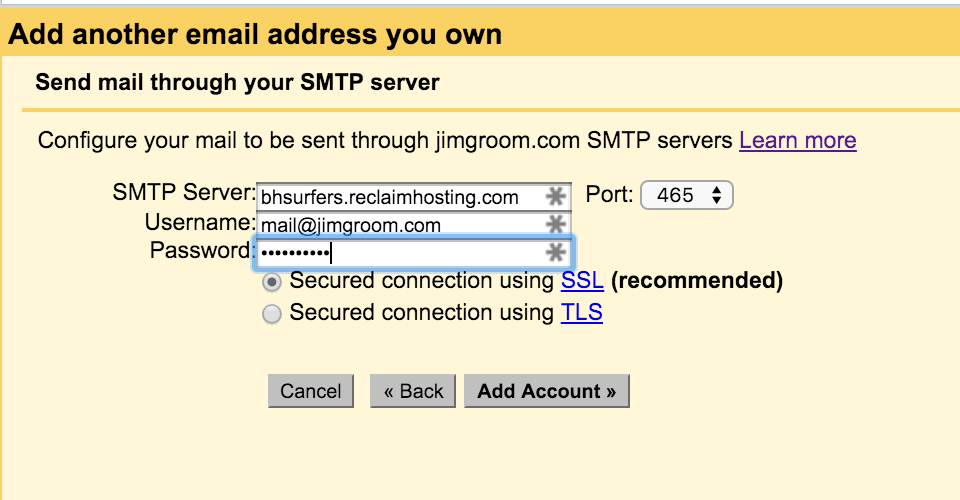
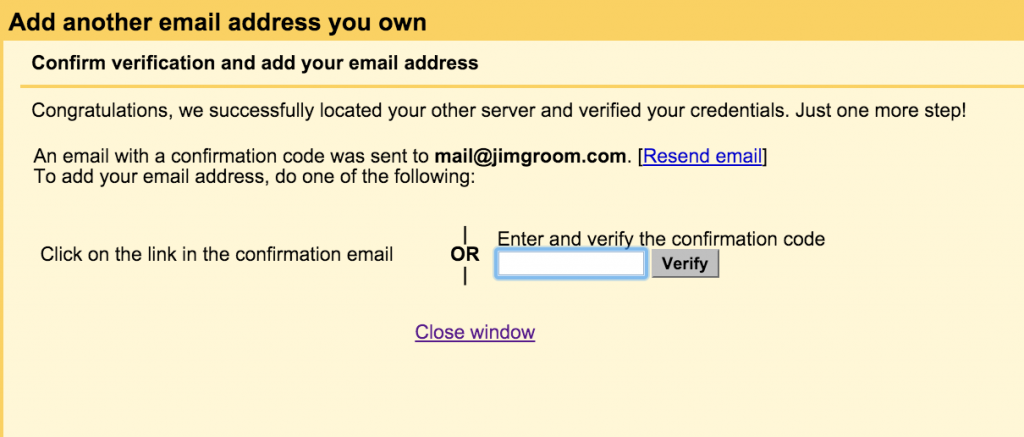
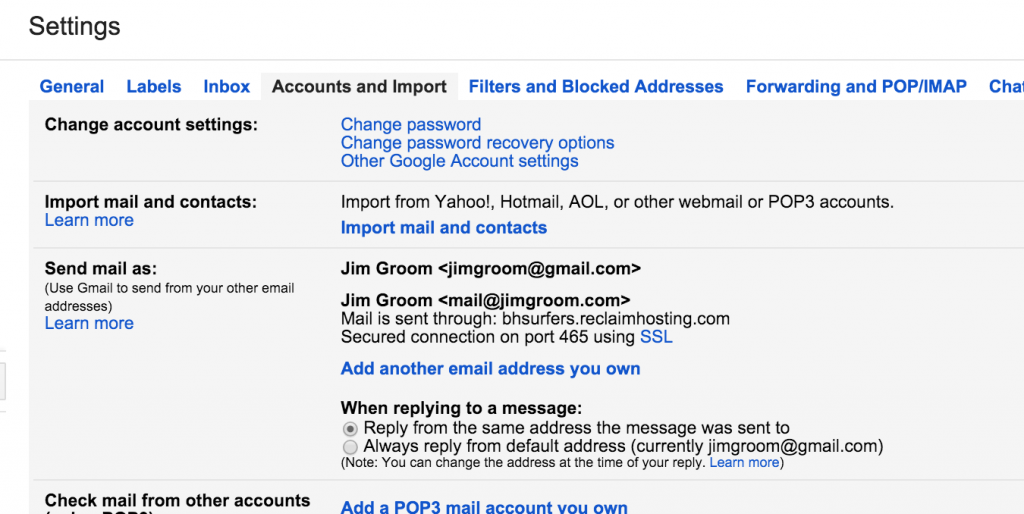

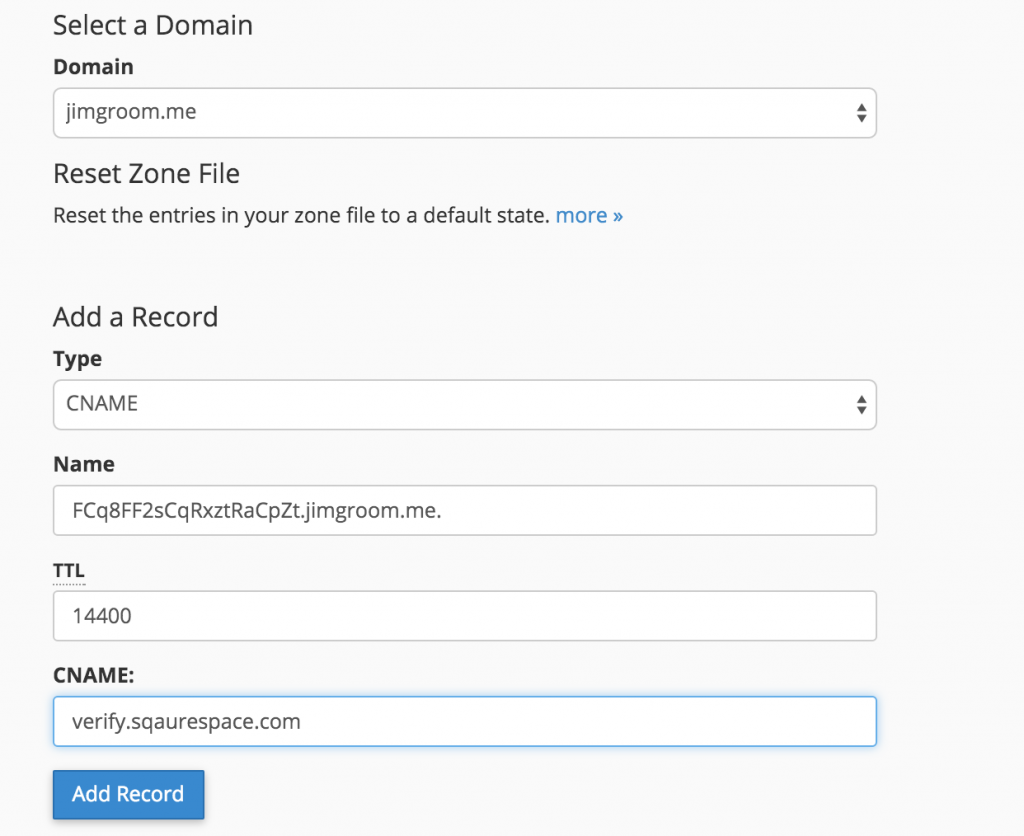
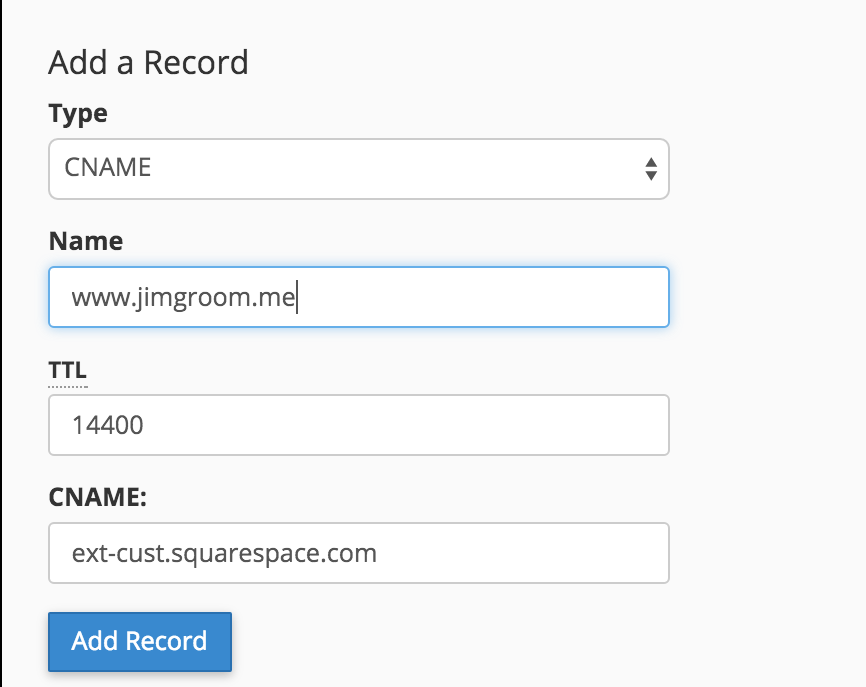
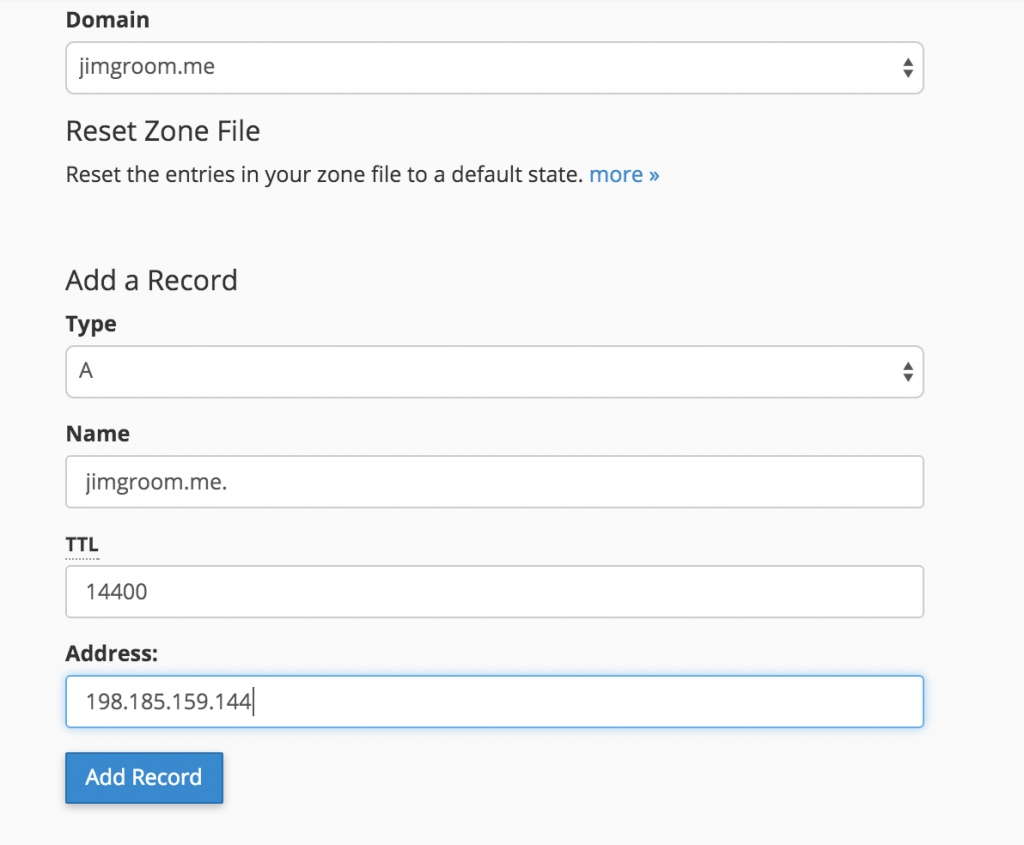
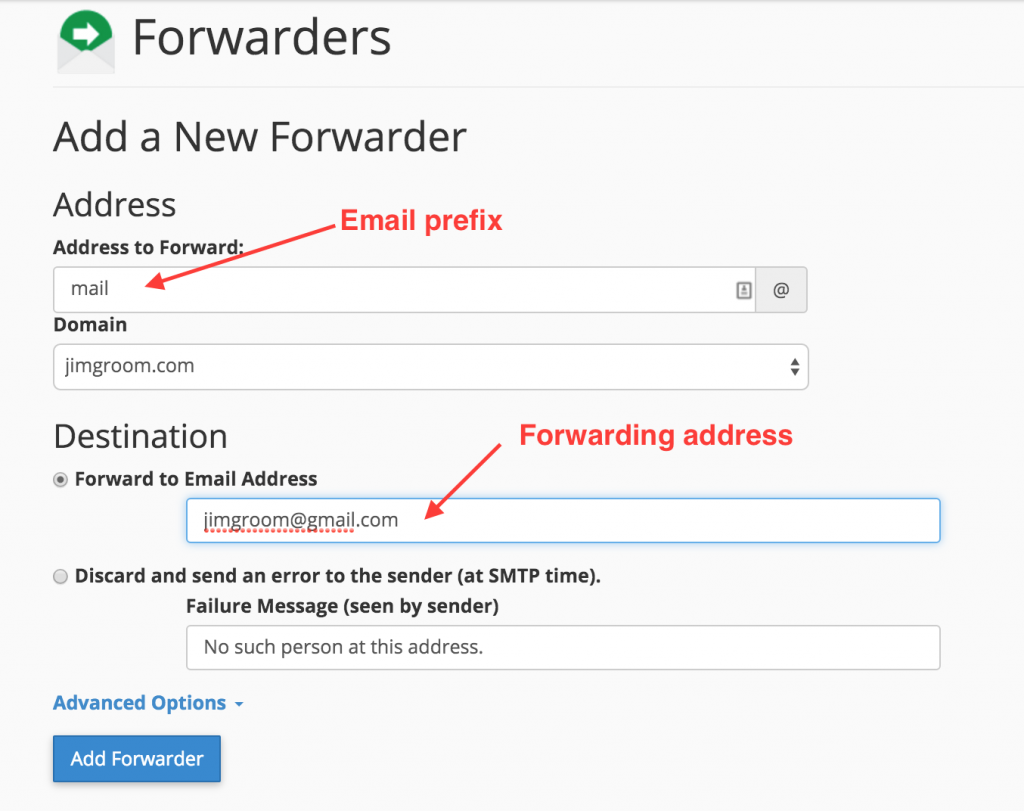 After you added the Forwarder, you should double check your addresses, and you should be all set.
After you added the Forwarder, you should double check your addresses, and you should be all set.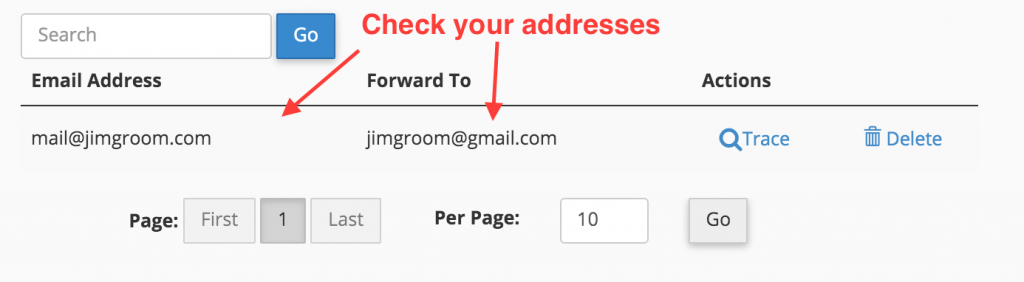

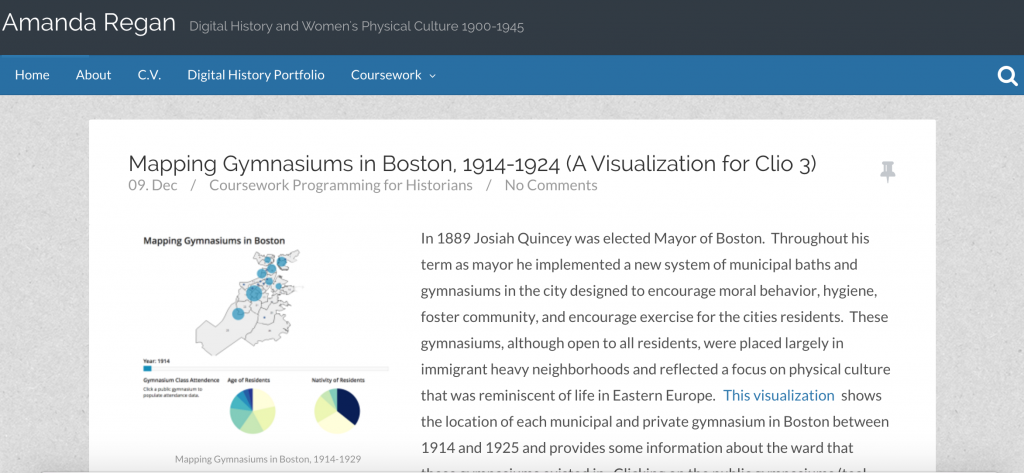
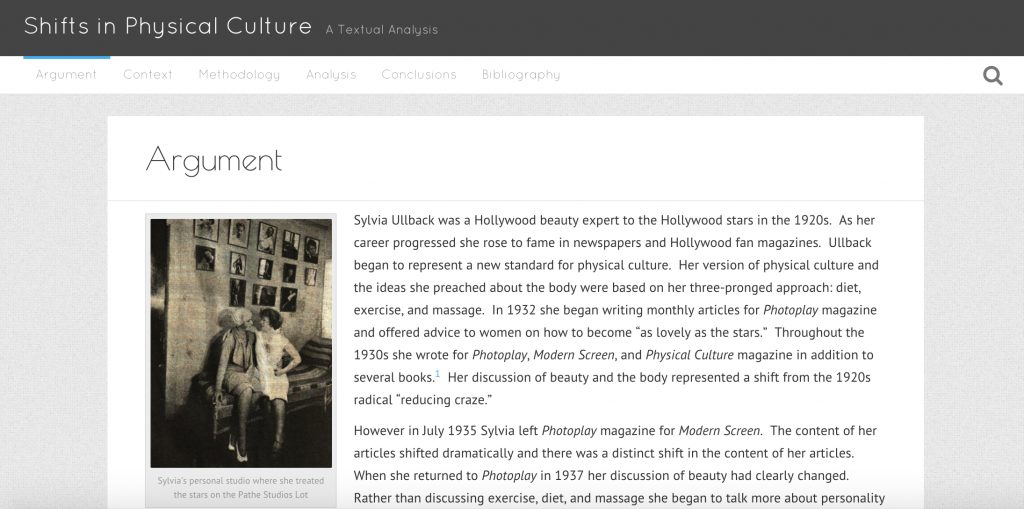

 I highly recommend this interview from back in 2008 that
I highly recommend this interview from back in 2008 that