
I am preparing a talk for Thursday that revisits a journal article Brian Lamb and I wrote in late 2008, early 2009 for the Universities and Knowledge Societies Journal (RUSC) titled “The Education of as Un-Artist…or is that the un-education of the technologist?” It’s an unorthodox approach to an article wherein we acknowledge from the outset we have no “synthetic theory” of what we talk about. Rather, we offer a series of vignettes of then current work happening in edtech that we thought was somehow important, while resisting any sense of an organizing theory or principle to wrap it up neatly. The article abstract is pretty awesome:
Two educational technologists and webloggers present a series of vignettes, contemplating the effects of modern networked communication on their practice. Recognizing their inability to construct a synthetic theory amidst the maelstrom, they curate a collection of observations and manifestos emphasizing themes of personal publishing, spontaneous collaborations, learning on the open web, and syndication.
In effect, we were creating a “maelstrom” of examples that we wanted folks to get sucked up into to get a sense of the chaotic nature of learning on the web. We highlighted what turns out to be a pretty interesting collection of examples, and I think we may very well be able to lay claim the first academic journal references to Massive Open Online Courses. Natch, we wrote about MOOCs before they were cool.
But, as I will explore in my talk on Thursday, so many of these vignettes are pieces that started to come together when a community of folks started to architect the online, open version of ds106 in the Spring of 2011. A “space of one’s own†,” class-based mashups, spontaneous connections, serendipitous collaborations, and the ever-venerable syndication bus can all be seen as the building block of ds106. Interesting how so many ideas that were percolating around this time, fueled by the excitement of EDUPUNK, remain exactly the things many of us are still working towards. A Space of One’s Own was instrumental to the personal cyberinfrastruscture at the heart of ds106 that enabled us to imagine a syndication bus we can build around it. A technical means to manage a distributed network of folks that share the work from their own space to a syndicated course hub. Spontaneous connections through Twitter hastags like #ds106 make for serendipitous collaborations and an amazingly distributed course experience.
So, as I am working through this presentation and revisiting some fairly strident language like this on the Syndication Bus:
The very logic of the LMS might be understood as a mausoleum for the internment of any and all possibilities for an individual to control, manage and openly share their own thinking with the community at large—it is within these darkly sealed crypts that you will find the mummified corpses of learning.
Alternatively, syndication buses represent a space through which individuals within a learning community can share their work through personal publishing platforms that they maintain ownership over. Rather than locking information into centralized systems, institutions should be designing a syndication-oriented framework that empowers its members to add their own syndicated voices to a larger, streaming conversation that can be filtered and visualized through semantic tags and categories.
I am reminded just how tightly we have begun to make syndication hubs work fairly seamlessly when it comes to ds106. For example, Remy Holden is having his students at University of Colorado, Denver sign-up for ds106 right now. He’s using the ds106 tag template for his course as an aggregator for students’ posts. And guess what, it’s pretty seamless. They complete a form asking for their name, institutional affiliation, blog URL, feed, and Twitter handle, and it’s all done.
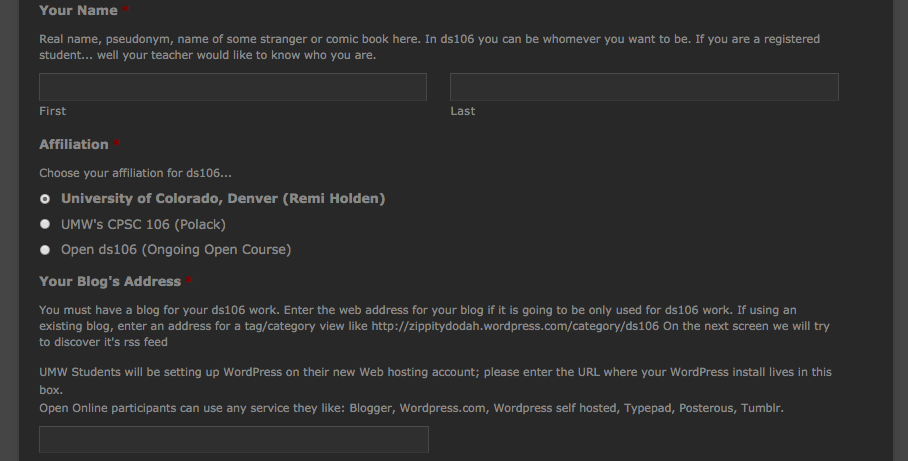
What’s cool is that for Remi’s students have blogs on everything from Tumblr to Blogger to WordPress.com to Wix to self-hosted sites. Yet, they’re all being added to FeedWordPress and syndicating into the ds106 site without major issues.‡ On top of that, when they select the radio button associating the feed with their course at sign-up, it automatically tags all their posts for that course. Those posts are then aggregated to a tag-based template page with course specific content in the sidebar. This is something Alan Levine figured out, and it’s really cool. All the posts for Remi Holden’s class are now tagged with cudenver15, and they show up at the URL: http://ds106.us/tag/cudenver15
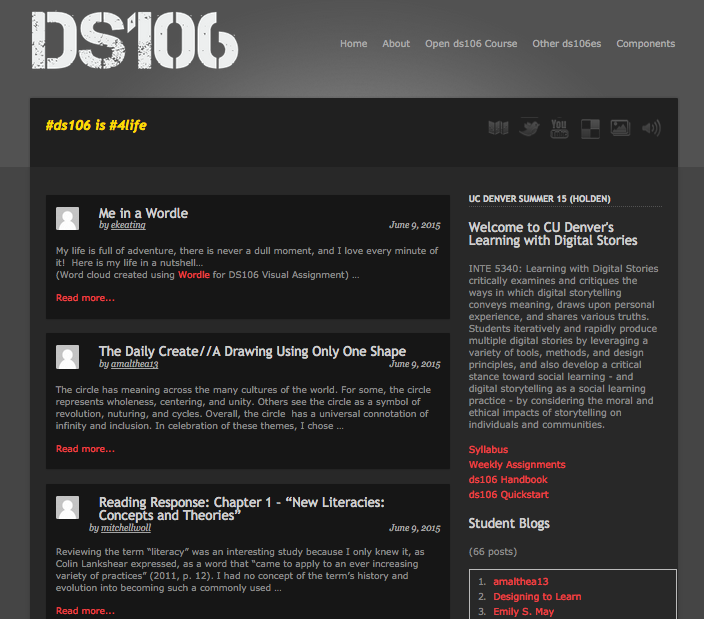
Alan added context specific code (and short codes) for the class tag which provide a quick, aggregated course page. Links to the syllabus, assignments, list of student blogs, how many posts, random comments, etc. It’s an awesome template that a professor can decide to use, or not. Either way, it acts as an aggregator that they can take the feed for and syndicate the posts where ever they want. The EDUGLU Syndication Bus in full effect aggregating anything that has a working RSS feed. Booya!
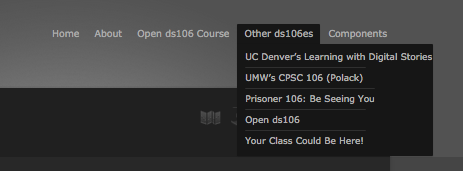 I had to do a few backend copy and pastes for the sidebar code to create a dynamic tag-based course page, but I imagine that could be automated so that a faculty member fills out the course information form at ds106.us and much of the tag-based template page is automated.
I had to do a few backend copy and pastes for the sidebar code to create a dynamic tag-based course page, but I imagine that could be automated so that a faculty member fills out the course information form at ds106.us and much of the tag-based template page is automated.
Alan has created some amazing instantiations of the syndication hub for a few years now. And as I revisit EDUGLU and the syndication bus yet again in preparation for my talk on Thursday, I am blown away by all the amazing progress that has happened in this arena over the last seven years since we wrote that article. ds106 is a model for online course design that is truly on and of the web. And it was built by many people, and tells a story of collaborative, community-based contributions that offers a powerful argument for experience-based design that studies the action of the whirlpool that is the web and cooperates with it rather than putting it back into a box.
The mission has remained clear, despite all the distractions and hype. Create a technical infrastructure that empowers both faculty and students to become the sovereign source of their online presence for teaching and learning. While at the same time, enabling quick, targeted aggregation and syndication of their work within a broader community context so they can explore, discover, feedback, and share. The syndication bus #4life.
_______________________________________________________
† I hadn’t committed to “domain of one’s own” yet, though I already coined the term by this point.
‡ One issue we should look at is allowing folks to edit the information they enter on the form in the event they need to change the feed—which a few do. That said, this introduces usernames and passwords that make the sign-up and barrier to entry a bit more cumbersome.













![ds106 in[SPIRE]](https://bavatuesdays.com/wp-content/uploads/2012/04/Picture-17-1024x598.png)

{kind=link}