Back in September I installed the On This Day plugin to start trying to review and clean-up the bava archive on a more regular basis. With almost 4,000 posts, this blog has accumulated a lot of jettisoned media and broken links, and while I understand things will inevitably fall apart on this fragile web, I have an unhealthy obsession with trying to keep up appearances. My original plan of checking the archives page every day proved a bit too ambitious, but I’ve been able to check-in now and again since September, and I must say it is a wild ride.
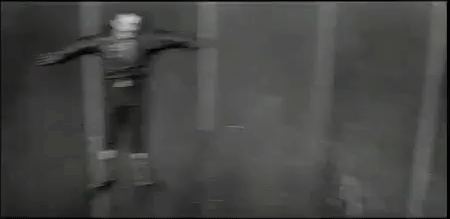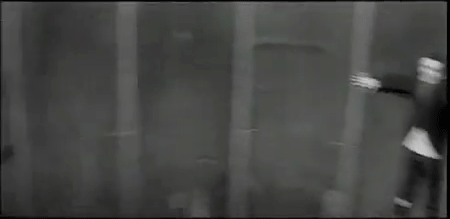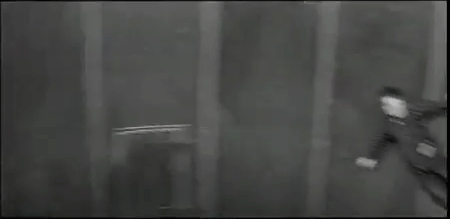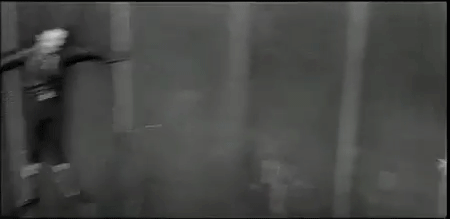 More than anything, I continue to be blown away by the fact that I don’t remember so much of it. Let me start with a telling example of the experience on a few levels. Going through the On This Page post links a few days ago I found a post I actually do remember writing about Spacesick’s “I Can Read Movies” book cover series during the height of the ds106 design assignment days. The post was riddled with dead links given the Flickr account originally housing the images of these amazing re-imagined movie book covers was no longer active. The account may have been victim of the shift to charging folks for larger accounts, but whatever the reason, the images were long gone.
More than anything, I continue to be blown away by the fact that I don’t remember so much of it. Let me start with a telling example of the experience on a few levels. Going through the On This Page post links a few days ago I found a post I actually do remember writing about Spacesick’s “I Can Read Movies” book cover series during the height of the ds106 design assignment days. The post was riddled with dead links given the Flickr account originally housing the images of these amazing re-imagined movie book covers was no longer active. The account may have been victim of the shift to charging folks for larger accounts, but whatever the reason, the images were long gone.
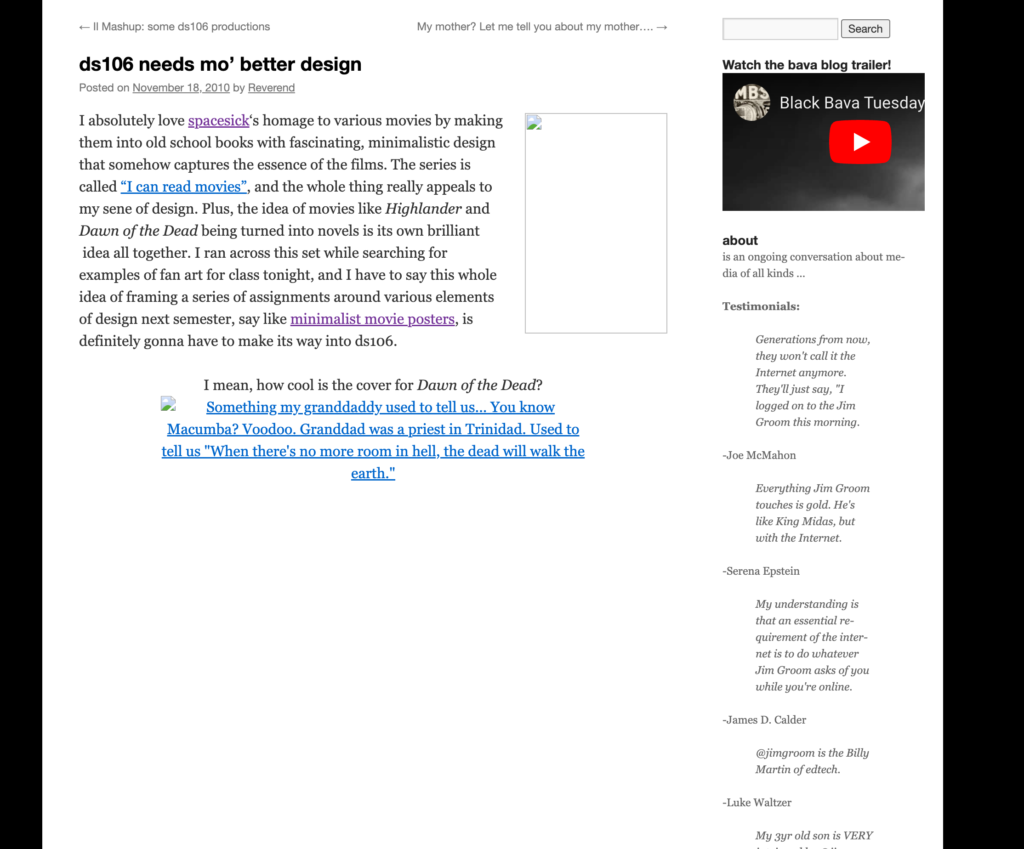
Screenshot of ds106 Needs Mo Better Design with wholes left from broken image links
So to try and fill the broken image gaps, I searched for any of the “I Can Read Movies” posters I referenced and embedded in that post. I found a few, but not all, but I also noticed some other “I Can Read Movies” titles while I was searching, and there was one that I thought was clever, the “I Can Read Alien” version:

After following the link I was brought to this post on bavatuesdays, turns out I created this book cover as a ds106 assignment almost 12 years ago, and after reading my own post I have only a vague memory. I said it already, but going through the blog archive is akin to experiencing some Memento-like creative amnesia—“I actually did that?” So that element of the experience is omnipresent, but it’s not all existential angst. Another element I found amazing was discovering to my pleasant surprise that the Dawn of the Dead cover I couldn’t find was readily available after searching my own blog on the Wayback Machine for the originalpost and hitting pay dirt thanks to a November 24, 2010 capture:
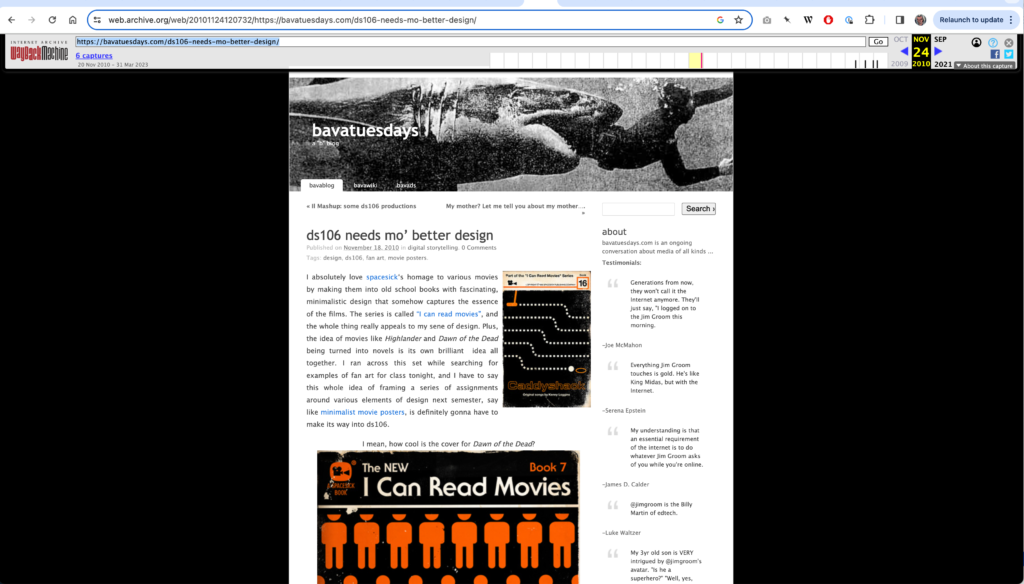
screenshot of the November 24, 2010 capture the Wayback Machine took of this blog post which captured all the now gone images
It’s so beautiful, a K2/Kubrick themed bavatuesdays no less!

More extensive screenshot of the post that was archive on the Wayback Machines with all the links
I was impressed how well they archived the Flickr images, the only thing not working was a dynamic slideshow I included of Spacesick’s book covers within an album on Flickr, but besides that it was perfect. What’s more, the capture does a great job reproducing the K2/Kubrick theme style of the bava at that time, as well as context specific sidebar updates. I never really used the Wayback machine for my own blog, but I have to say the Internet Archive is #4life!

Screenshot of bava post with just captions but no images from Google Maps live photos that came from a tumblr that collected them
After that, I resurrected a post with a ton of broken image links from a Tumblr account highlighting all the weird images captured by the Google Maps photo cars. In fact, we had a ds106 class wherein we captioned the photos, which I shared in this post, and they are pretty wild. I cannot believe we spent an entire class session on this, but at the same time how awesome! 🙂 Well, turns out the Wayback Machine captured almost every image in that post, and they were right there for me to browse, and ultimately copy over to my blog:
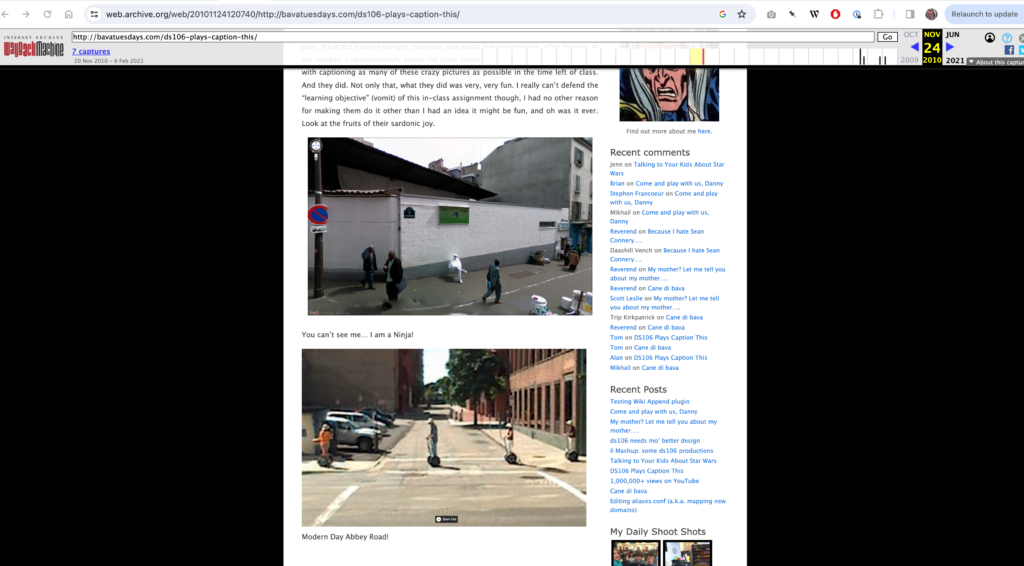
Screenshot of a blog post on bavatuesdays including Google Maps images captioned by students. This was when Google Maps started adding a live view to its interface
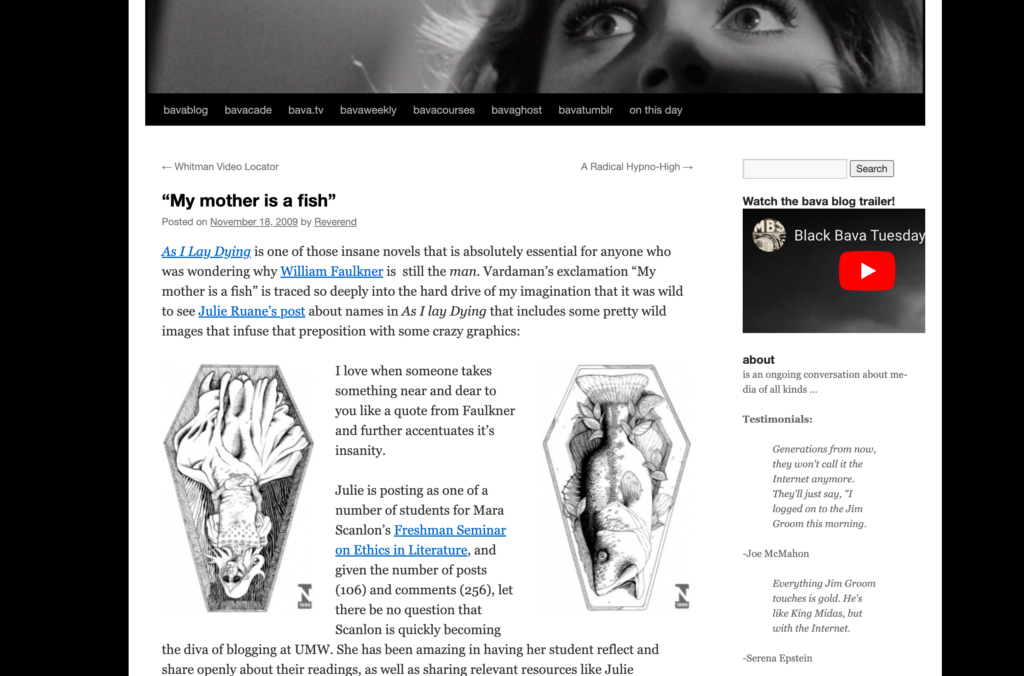
This was a pretty amazing discovery, and there was another post I had unearthed that was missing images so I figured, “Why not?” So I rolled the dice, but no luck. Upon further inspection I realized I was linking to a UMW Blogs-hosted course about Ethics in Literature by the great Mara Scanlon. But wait, UMW Blogs was recently archived by those fine folks, so why not give that Webrecorder instance a search. And wham, dam, thank you UMW, I found the Ethics and Lit blog in all its glory:
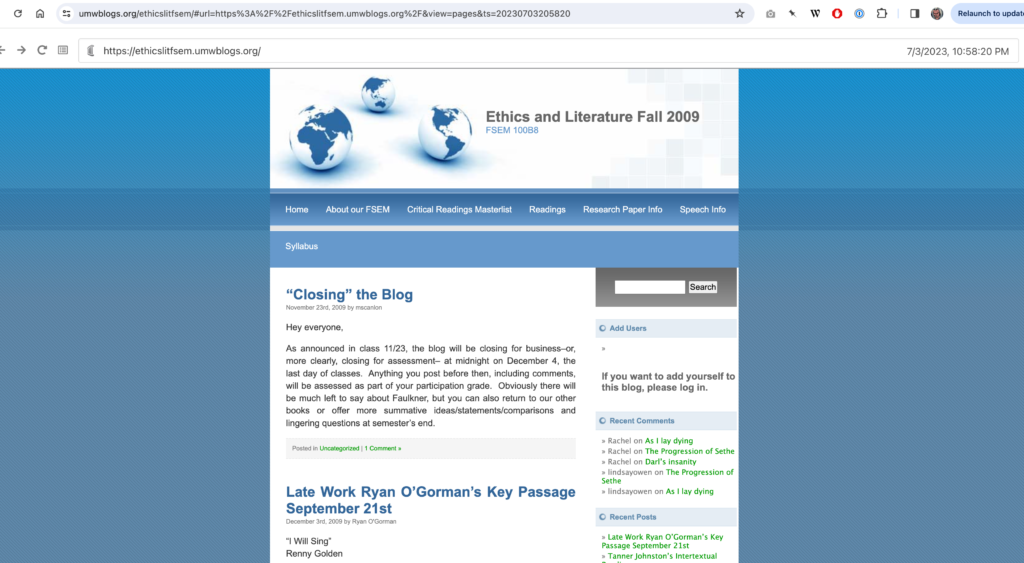
Screenshot Mara Scanlon’s Ethics and Literature course blog from Fall 2009
Now to find the images about Faulkner’s As I Lay Dying wherein Vardeman compares his dead mother to a fish. Search…..Bingo!
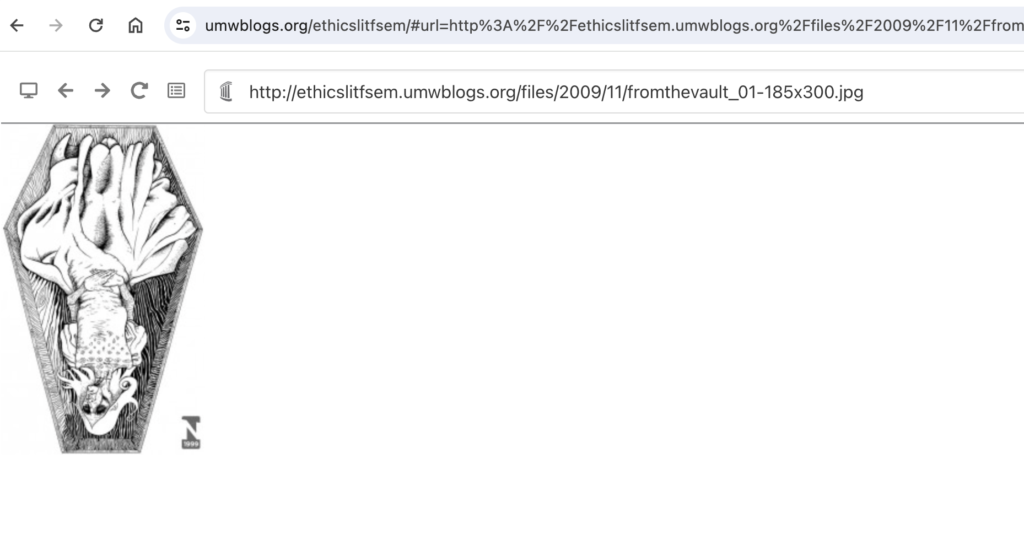
Image of a fish-like corpse in a coffin as a interpretation of a scene from Faulkner’s As I Lay Dying
So I copy that image and the other into my own blog, which had holes in the tapestry, and…
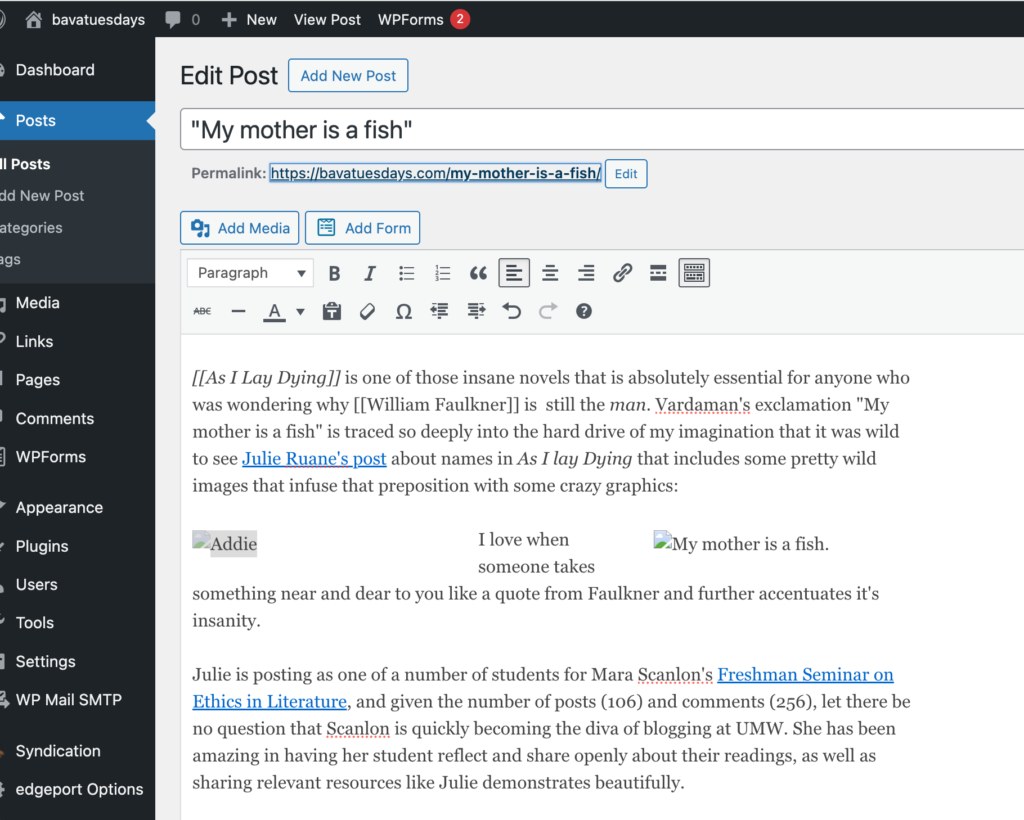
Voila, the bava is whole again!
The fact that Reclaim Hosting could partner with UMW on preserving that platform makes me ridiculously happy. I love it conceptually, ideologically, and even more in practice—which this post attests to.
These recent raids of the bava archives have me excited about what I might find next, and even more now given might be able to actually future-proof quite a bit of the media on the bava thanks to organizations like Internet Archive and UMW Blogs—I love those two flavors side-by-side in that statement 🙂
The things you discover and realize by reflecting on a few love letters sent to the web years and years ago.

Me driving back through my GIF posts in the bava archives
Anyway, I’ve also realized my blogging is pretty thematic: I write about WordPress and UMW Blogs a lot early on; then ds106 takes over; then Reclaim Hosting—not that surprising given it’s a document of my work over 18 years. But one theme I particularly enjoyed on my recent travels into the archive were all the writings about GIFs. In fact, a couple of my very favorite bava posts are just GIFs. The “Give it Up for the GIF” post written on November 17, 2012 may be my favorite post of all time given it highlights all the GIFs I made during a two-year, quite intensive run of ds106:
Give it Up for the GIF
I also documented the moment Zach Davis shared the “If We Don’t, Remember Me” tumblr that gave GIFs an entirely new world of possibilities with a deeply meditative aesthetic that highlights the creative and instructional power of the format.

My mother? Let me tell you about my mother….
And then there is the lamenting about not making as good a GIF as I used to, which still manages a decent GIF from Magnificent Obsession:

In 2011 and 2012 there were so many GIFs on the bava, and it for me was a direct link to the creative excitement that came out of ds106, quite possibly this blog at its creative peak—definitely if it comes to sheer number of unique, exciting posts about almost anything I found interesting culturally.

There is much more I can say, and I have earmarked a whole bunch of posts that highlight some of the other themes as they are fleshed out with more research, but for now let volume 1 of the archive reflections highlight the magic of the GIF, something that since 2010/2011 has become an widely accepted way of communicating digitally, and one that I love, love, love.

What an amazing first issue 🙂